

集合
1. Java 集合框架
1.1 将集合的结构与实现分离
Java 集合类库也将接口(interface)与实现(implementation)分离。
例如队列接口的最简形式类似下面的代码:
public interface Queue<E> {// a simplified form of the interface in the standard library
void add(E element);
E remove();
int size();
}
这个接口并没有说明队列是如何实现的,通常有两种实现方式:一种是使用循环数组;另一种是使用链表。
这样做的好处是:当在程序中使用队列时,一旦构建了集合,就不需要知道究竟使用了哪种实现。因此,只有在构建集合对象的时候,使用具体的类才有意义。可以使用接口类型存放集合的引用:
Queue<Customer> expressLane = new CircularArrayQueue<>(100);
expressLane.add(new Customer("Harry"));
这样一来,一旦改变了想法,就可以轻松的使用另外一种不同的实现。只需要对程序的一个地方做出修改,即调用构造器的地方。如果觉得LinkedListQueue是个更好的选择,就将代码修改为:
Queue<Customer> expressLane = new LinkedListQueue<>(100);
expressLane.add(new Customer("Harry"));
注:循环数组是一个有界集合,即容量有限。如果程序中要收集的对象数量没有上限,就最好使用链表来实现
1.2 Collection 接口
在 Java 类库中,集合类的基本接口是Collection接口,它有两个基本方法:
public interface Collection<E> {
boolean add(E element);
Iterator<E> iterator();
...
}
方法add用于向集合中添加元素。如果添加元素确实改变了集合就返回true,如果集合没有发生变化就返回false。
方法iterator用于返回一个实现了Iterator接口的对象,可以使用这个迭代器依次访问集合中的元素。
1.3 迭代器
接口Iterator包含了 4 个方法:
public interface Iterator<E> {
E next();
boolean hasNext();
void remove();
default void forEachRemaining(Consumet<? super E> action);
}
用for each循环可以简练的表示循环操作:
for (String element : c) {
do something with element
}
编译器简单的将for each循环翻译为带有迭代器的循环。for each循环可以与任何实现了Iterable接口的对象一起工作,这个接口只包含一个抽象方法:
public interface Iterable<E> {
Iterator<E> iterator();
...
}
Collection接口扩展了Iterable接口。因此,对于标准类库中的任何集合,对可以使用for each循环。
在 Java SE 8 中,甚至不用写循环,可以调用
forEachRemaining方法并提供一个 lambda 表达式:
iterator.forEachRemaining(element -> do something with element);
注:Java 迭代器应该被视作位于两个元素之间。当调用
next时,迭代器就越过下一个元素,并返回刚刚越过的那个元素的引用,而Iterator接口的remove方法将会删除上次调用next方法时返回的元素。
例如,删除字符串集合中的第一个元素:
Iterator<String> it = c.iterator();
it.next(); // skip over the first element
it.remove(); // now remove it
类似的,要想删除两个相邻的元素,必须先调用next越过将要删除的元素:
it.remove();
it.next();
it.remove();
1.4 泛型实用方法
由于Collection和Iterator都是泛型接口,可以编写操作任何集合类型的实用方法:
public static <E> boolean contains(Collection<E> c, Object obj) {
for (E element : c)
if (element.equals(obj))
return true;
return false;
}
int size()
boolean isEmpty()
boolean contains(Object obj)
boolean containsAll(Collection<?> c)
boolean equals(Object other)
boolean addAll (Collection<? extends E> from)
boolean remove(Object obj)
boolean removeAll(Collection<?> c)
void clear()
boolean retainAll(Col1ection<?> c)
Object[] toArray()
<T> T[] toArray(T[] arrayToFill)
1.5 集合框架中的接口
Java 集合框架为不同类型的集合定义了大量接口:
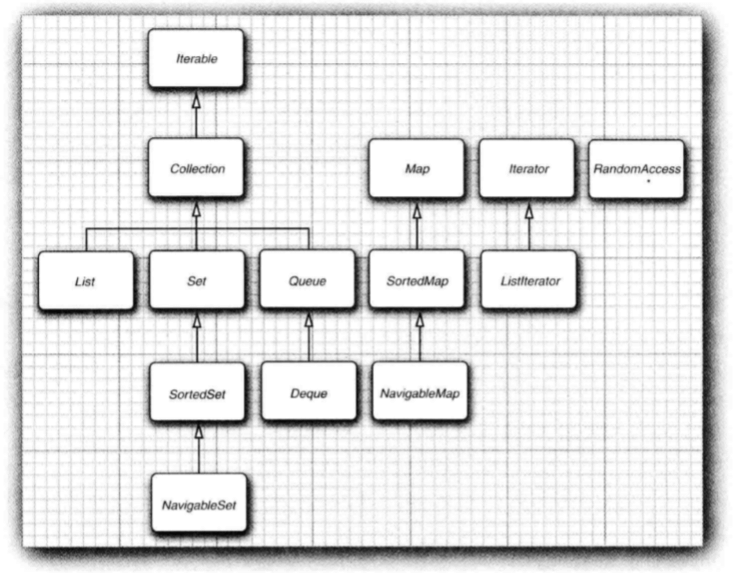
集合有两个基本接口:Collection和Map:
boolean add(E element) // 用于集合
iterator.next()
V put(K key, V value) // 用于映射
V get(K key)
2. 线性表与队列
下面展示了 Java 类库中的集合,并简要描述了每个集合类的用途。除了以Map结尾的类之外,其他类都实现了Collection接口,而以Map结尾的类则实现了Map接口:
- ArrayList:一种可以动态增长和缩减的索引序列
- LinkedList:一种可以在任何位置进行高效的插入和删除操作的有序序列
- ArrayQueue:一种用循环数组实现的双端队列
- HashSet:一种没有重复元素的无序集合
- TreeSet:一种有序集
- EnumSet:一种包含枚举类型值的集
- LinkedHashSet:一种可以记住元素插入次序的集
- PriorityQueue:一种允许高效删除最小元素的集合
- HashMap:一种存储键/值关联的数据结构
- TreeMap:一种键值有序排列的映射表
- EnumMap:一种键值属于枚举类型的映射表
- LinkedHashMap:一种可以记住键/值项并添加次序的映射表
- WeakHashMap:一种其值无用武之地后可以被 GC 回收的映射表
- IdentityHashMap:一种用
==而不是用equals比较键值的映射表
2.1 链表 LinkedList
在 Java 中,所有链表(Linked List)都是双向链接(Doubly Linked)的,即每个节点还存放着指向前驱节点的引用。
例如下面的代码示例,先添加 3 个元素,然后再将第 2 个元素删除:
import java.util.Iterator;
import java.util.LinkedList;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> staff = new LinkedList<>();
staff.add("Amy");
staff.add("Bob");
staff.add("Carl");
System.out.println(staff);
Iterator iterator = staff.iterator();
String first = iterator.next().toString();
String second = iterator.next().toString();
iterator.remove();
for (String name : staff) {
System.out.println(name);
}
}
}
------
[Amy, Bob, Carl]
Amy
Carl
Process finished with exit code 0
但是,链表与泛型集合有一个重要的区别:链表是一个有序集合(Ordered Collection),每个对象的位置十分重要。
关于 Java 中
Iterator和ListIterator的区别,可以参考 Java 中 ListIterator 和 Iterator 详解与辨析 | CSDN
另外,链表不支持快速的随机访问。如果要查看链表中第n个元素,就必须从头开始,越过n-1个元素,没有捷径可走。鉴于这个原因,在程序需要采用整数索引访问元素时,通常不会采用链表而会选择数组,因为LinkedList对象根本不做任何缓存位置信息的操作。
package linkedList;
import java.util.*;
/**
* This program demonstrates operations on linked lists.
*
* @author Cay Horstmann
* @version 1.11 2012-01-26
*/
public class LinkedListTest {
public static void main(String[] args) {
List<String> a = new LinkedList<>();
a.add("Amy");
a.add("Carl");
a.add("Erica");
List<String> b = new LinkedList<>();
b.add("Bob");
b.add("Doug");
b.add("Frances");
b.add("Gloria");
// merge the words from b into a
ListIterator<String> aIter = a.listIterator();
Iterator<String> bIter = b.iterator();
while (bIter.hasNext()) {
if (aIter.hasNext()) aIter.next();
aIter.add(bIter.next());
}
System.out.println(a);
// remove every second word from b
bIter = b.iterator();
while (bIter.hasNext()) {
bIter.next(); // skip one element
if (bIter.hasNext()) {
bIter.next(); // skip next element
bIter.remove(); // remove that element
}
}
System.out.println(b);
// bulk operation: remove all words in b from a
a.removeAll(b);
System.out.println(a);
}
}
------
[Amy, Bob, Carl, Doug, Erica, Frances, Gloria]
[Bob, Frances]
[Amy, Carl, Doug, Erica, Gloria]
Process finished with exit code 0
2.2 数组列表 ArrayList
集合类库提供了ArrayList类,这个类也实现了List接口。ArrayList封装了一个动态再分配的对象数组。
Vector 类的所有方法都是同步的,可以由两个线程安全的访问一个 Vector 对象。但是,如果由一个线程访问 Vector,代码要在同步操作上耗费大量的时间。而 ArrayList 方法不是同步的,因此,建议在不需要同步的时候使用
ArrayList,而不要使用Vector。
2.3 散列集 HashSet
散列表(Hash Table)可以快速的查找所需要的对象,而忽略元素出现的次序。散列表为每个对象计算一个整数,称为散列码(Hash Code)。散列码是由对象的实例域产生的一个整数。
在 Java 中,散列表用链表数组实现。每个链表被称为桶(bucket)。要想查找表中对象的位置,就要先计算它的散列码,然后与桶的总数取余,所得到的结果就是保存这个元素的桶的索引。
当然,有时候会遇到桶被占满的情况,这种现象被称为散列冲突(hash collision)。
在 Java SE 8 中,桶满时会从链表变为平衡二叉树。
Java 集合类库提供了一个HashSet类,它实现了基于散列表的集,可以用add方法添加元素。contains方法已经被重新定义,用来快速的查看是否某个元素已经出现在集中。它只在某个桶中查找元素,而不必查看集合中的所有元素。
package set;
import java.util.*;
/**
* This program uses a set to print all unique words in System.in.
*
* @author Cay Horstmann
* @version 1.12 2015-06-21
*/
public class SetTest {
public static void main(String[] args) {
Set<String> words = new HashSet<>(); // HashSet implements Set
long totalTime = 0;
try (Scanner in = new Scanner(System.in)) {
while (in.hasNext()) {
String word = in.next();
long callTime = System.currentTimeMillis();
words.add(word);
callTime = System.currentTimeMillis() - callTime;
totalTime += callTime;
}
}
Iterator<String> iter = words.iterator();
for (int i = 1; i <= 20 && iter.hasNext(); i++)
System.out.println(iter.next());
System.out.println(". . .");
System.out.println(words.size() + " distinct words. " + totalTime + " milliseconds.");
}
}
2.4 树集 TreeSet
树集(TreeSet)与散列集十分类似,不过比散列集有所改进。树集是一个有序集合,可以以任意顺序将元素插入到集合中。在对集合进行遍历时,每个值将自动的按照字典顺序呈现:
import java.util.SortedSet;
import java.util.TreeSet;
public class Main {
public static void main(String[] args) {
SortedSet<String> sorter = new TreeSet<>(); // TreeSet implements SortedSet
sorter.add("Bob");
sorter.add("Amy");
sorter.add("Carl");
for (String s : sorter) {
System.out.println(s);
}
}
}
------
Amy
Bob
Carl
Process finished with exit code 0
正如TreeSet类名所示,排序是用树结构(红黑树)完成的。每次将一个元素添加到树中时,都被放置在正确的排序位置上。因此,迭代器总是以排好序的顺序访问每个元素。
添加元素到树集中的速度比散列表中要慢,不过还是比数组或链表快。另外,要使用树集,必须能够比较元素,这些元素必须实现
Comparable接口,或者构造集的时候必须提供一个Comparator
2.5 队列与双端队列
队列(Queue)可以让我们有效的在尾部添加一个元素,在头部删除一个元素。有两个端头的队列,即双端队列(Deque),可以有效的在头部和尾部同时添加或删除元素,但不支持在队列中间添加元素。
在 Java SE 6 中引入了Deque接口,并由ArrayDeque和LinkedList类实现。这两个类都提供了双端队列,而且在必要时可以增加队列的长度。
Queue<String> student = new LinkedList<>();
Deque<String> teacher = new ArrayDeque<>();
Deque<String> employee = new LinkedList<>();
2.6 优先级队列
优先级队列(priority queue)中的元素可以按照任意的顺序插入,却总是按照排序的顺序进行检索。也就是说,无论何时调用remove方法,总会获得当前优先级队列中最小的元素。
优先级队列使用了一个优雅且高效的数据结构,称为堆(heap)。堆是一个可以自我调整的二叉树,对树执行添加add和删除remove操作,可以让最小的元素移动到根,而不必花费时间对元素进行排序。
使用优先级队列的典型示例是任务调度。每一个任务有一个优先级,任务以随机顺序添加到队列中。每当启动一个新任务的时候,就将优先级最高的任务从队列中删除
import java.time.LocalDate;
import java.util.PriorityQueue;
public class Main {
public static void main(String[] args) {
PriorityQueue<LocalDate> pq = new PriorityQueue<>();
pq.add(LocalDate.of(1906, 12, 9)); // G. Hopper
pq.add(LocalDate.of(1815, 12, 10)); // A. Lovelace
pq.add(LocalDate.of(1903, 12, 3)); // J. von Neumann
pq.add(LocalDate.of(1910, 6, 22)); // K. Zuse
System.out.println("Iterating over elements...");
for (LocalDate date : pq) {
System.out.println(date);
}
System.out.println("Removing elements...");
while (!pq.isEmpty()) {
System.out.println(pq.remove());
}
}
}
3. 映射
映射(map)用来存放键/值对,如果提供了键,就能查找到值。
3.1 基本映射操作
Java 类库为映射提供了两个通用的实现:HashMap和TreeMap,这两个类都实现了Map接口。
HashMap对键进行散列,TreeMap用键的整体顺序对元素进行排序,并将其组织成搜索树。散列或比较函数只能作用于键,与键关联的值不能进行散列或比较。
与集一样,
HashMap比TreeMap稍微快一些。如果不需要按照排列顺序访问键,就最好选择散列
Map<String, Employee> staff = new HashMap<>(); // HashMap implements Map
Employee harry = new Employee("Harry Hacker", 8000, 1990, 11, 07);
staff.put("987-98-9996", harry);
// 使用键来检索对象,如果不存在则返回 null
String id = "987-98-9996";
Employee e = staff.get(id);
还可以设定一个默认值,用作映射中不存在的键:
Map<String, Integer> scores = ...;
int score = scores.get(id, 0); // Gets 0 if the id is not present
- 键必须是唯一的,不能对同一个键存放两个值。如果对同一个键两次调用
put方法,则第二个值就会覆盖第一个值 remove方法用于从映射中删除给定键对应的元素size方法用于返回映射中的元素个数- 可以使用 lambda 表达式和
forEach方法,迭代处理映射的键和值
scores.forEach((k, v) ->
System.out.println("key=" + k + "value=" + v));
如下的示例代码显示了映射的操作过程:
package map;
import java.util.*;
/**
* This program demonstrates the use of a map with key type String and value type Employee.
* @version 1.12 2015-06-21
* @author Cay Horstmann
*/
public class MapTest
{
public static void main(String[] args)
{
Map<String, Employee> staff = new HashMap<>();
staff.put("144-25-5464", new Employee("Amy Lee"));
staff.put("567-24-2546", new Employee("Harry Hacker"));
staff.put("157-62-7935", new Employee("Gary Cooper"));
staff.put("456-62-5527", new Employee("Francesca Cruz"));
// print all entries
System.out.println(staff);
// remove an entry
staff.remove("567-24-2546");
// replace an entry
staff.put("456-62-5527", new Employee("Francesca Miller"));
// look up a value
System.out.println(staff.get("157-62-7935"));
// iterate through all entries
staff.forEach((k, v) ->
System.out.println("key=" + k + ", value=" + v));
}
}
3.2 更新映射项
当更新一个之前不存在的键值时会抛出NullPointerException异常,作为补救,可以使用getOrDefault方法设置一个默认值:
counts.put(word, counts.getOrDefault(word, 0) + 1);
或者首先调用putIfAbsent方法,当原先的键不存在时才会放入一个值:
counts.putIfAbsent(word, 0);
counts.put(word, counts.get(word) + 1);
还可以使用merge方法来简化操作。如果键原先不存在,则下面的调用:
counts.merge(word, 1, Integer::sum);
将把word与1关联,否则使用Integer::sum函数组合将原值和1相加求和。
3.3 映射视图
集合框架不认为映射本身是一个集合。不过,可以得到映射的视图(view)——这是实现了Collection接口或某个子接口的对象。
有三种视图:键集、值集合(不是一个集)以及键/值对集。键和键/值对可以构成一个集,因为映射中一个键只能有一个副本。下面的方法:
Set<K> keySet()
Collection<V> values()
Set<Map.Entry<K, V>> entrySet()
会分别返回这三个视图。需要注意的是,keySet不是HashSet或者TreeSet,而是实现了Set接口的另外某个类的对象。Set接口扩展了Collection接口,因此可以像使用集合一样使用ketSet。例如可以枚举一个映射的所有键:
Set<String> keys = map.keySet();
for (String key: keys) {
do something with key
}
如果想同时查看键和值,可以通过枚举条目来避免查找值:
for (Map.Entry<String, Employee> entry: staff.entrySet()) {
String k = entry.getKey();
Employee v = entry.getValue();
do something with k, v
}
现在,还可以使用forEach方法:
counts.forEach((k, v) -> {
do something with k, v
})
3.4 弱散列映射
对于类WeakHashMap,如果有一个值,假定对该值对应的键的最后一次引用已经消亡,不再有任何途径引用这个值的对象了,这时这个键/值对就会被 GC 回收。
3.5 LinkedHashSet 与 LinkedHashMap
LinkedHashSet与LinkedHashMap两个类用来记住插入元素项的顺序。当条目插入到散列表中时,就会被并入到双向链表中:
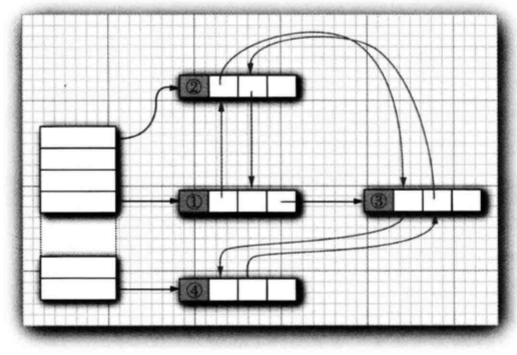
3.6 枚举集与映射
EnumSet是一个枚举类型元素集的高效实现。可以使用静态工厂方法构造这个集:
enum Weekday { MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY, SUNDAY };
EnumSet<Weekday> always = EnumSet.allOf(Weekday.class);
EnumSet<Weekday> never = EnumSet.noneOf(Weekday.class);
EnumSet<Weekday> workday = EnumSet.range(Weekday.MONDAY, Weekday.FRIDAY);
EnumSet<Weekday> mwf = EnumSet.of(Weekday.MONDAY, Weekday.WEDNESDAY, Weekday.FRIDAY);
EnumMap是一个键类型为枚举类型的映射,可以直接且高效的用一个值数组实现。在使用时,需要在构造器中指定键类型:
EnumMap<Weekday, Employee> personInCharge = new EnumMap<>(Weekday.class);
3.7 标识散列映射
在类IdentityHashMap中,键的散列值不是用hashCode函数计算的,而是用System.identityHashCode方法计算的。这是Object.hashCode方法根据对象的内存地址来计算散列码时所使用的方式。而且,在对两个对象进行比较时,IdentityHashMap类使用==,而不是equals,所以不同的键对象,即使内容相同,也被视为是不同的对象。
4. 视图与包装器
4.1 轻量级集合包装器
Arrays 类的静态方法asList将返回一个包装了普通 Java 数组的 List 包装器,这个方法可以将数组传递给一个期望得到列表或者集合参数的方法:
Card[] cardDeck = new Card[52];
...
List<Card> cardList = Arrays.asList(cardDeck);
List<String> names = Arrays.asList("Amy", "Bob", "Carl");
4.2 子范围
可以为很多集合建立子范围(subrange)视图:
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> names = new ArrayList<>();
names.add("Abel");
names.add("Bob");
names.add("Carl");
List group2 = names.subList(0, 2);
System.out.println(group2);
group2.clear();
System.out.println(names);
System.out.println(group2);
}
}
------
[Abel, Bob]
[Carl]
[]
Process finished with exit code 0
对于有序集和映射,可以使用排序顺序而不是元素位置建立子范围:
// 有序集
SortedSet<E> subSet(E from, E to)
SortedSet<E> headSet(E to)
SortedSet<E> tailSet(E from)
// 有序映射
SortedMap<K, V> subMap(K from, K to)
SortedMap<K, V> headMap(K to)
SortedMap<K, V> tailMap(K from)
4.3 不可修改的视图
Collections 还有几个方法,用于产生集合的不可修改视图(unmodifiable views)。这些视图对现有集合增加了一个运行时检查,如果发现试图对集合进行修改,就抛出一个异常,同时这个集合将保持未修改的状态:
Collections.unmodifiableCollection Collections.unmodifiableList Collections.unmodifiableSet Collections.unmodifiableSortedSet Collections.unmodifiableNavigableSet Collections.unmodifiableMap Collections.unmodifiableSortedMap Collections.unmodifiableNavigableMap
...
List<String> staff = new LinkedList<>();
...
lookAt(Collections.unmodifiableList(staff));
4.4 同步视图
例如,Collections 类的静态synchronizedMap方法可以将任何一个映射表转换成具有同步访问方法的 Map:
Map<String, Employee> map = Collections.synchronizedMap(new HashMap<String, Employee>);
这样一来,就可以由多线程访问map对象了。
4.5 受查视图
List<String> safeStrings = Collections.checkedList(strings, String.class);
视图的add方法将检测插入的对象是否属于给定的类。如果不属于给定的类,就立即抛出一个ClassCastException。
5. 算法
可以将max方法实现为能够接收任何实现了Collections接口的对象:
public static <T extends Comparable> T max(Collection<T> c) {
if (c.isEmpty()) throw new NoSuchElementException();
Iterator<T> iter = c.iterator();
T largest = iter.next();
while (iter.hasNext()) {
T next = iter.next();
if (largest.compareTo(next) < 0)
largest = next;
}
return largest;
}
5.1 排序与混排
Collections 类中的sort方法可以对实现了List接口的集合进行排序:
List<String> staff = new LinkedList<>();
// fill collection
Collections.sort(staff);
这个方法假定列表元素实现了*8Comparable接口。如果想采用其他方式对列表进行排序,可以使用List接口的sort方法并传入一个Comparator对象**:
staff.sort(Comparator.comparingDouble(Employee::getSalary));
// 逆序排
staff.sort(Comparator.reverseOrder());
staff.sort(Comparator.comparingDouble(Employee::getSalary).reversed());
5.2 二分查找
Collections 类的binarySearch方法实现了二分查找算法。需要注意的是,集合必须是排好序的,否则算法将返回错误的答案。要想查找某个元素,必须提供集合(实现List接口)以及要查找的元素。如果集合没有采用Comparable接口的compareTo方法进行排序,就还要提供一个比较器对象:
i = Collections.binarySearch(c, element);
i = Collections.binarySearch(c, element, comparator);
只有采用随机访问,二分查找才有意义。如果必须利用迭代方式来一次次的遍历链表,二分查找就完全失去了优势,退化为线性查找
5.3 简单算法
略
5.4 批操作
coll1.removeAll(coll2);
coll1.retainAll(coll2); // 删除所有未在`coll2`中出现的元素
例如求a和b的交集:
Set<String> result = new HashSet<>(a);
result.retainAll(b);
5.5 集合与数组的转换
将数组转换为集合,可利用Arrays.asList包装器:
String[] values = ...;
HashSet<String> staff = new HashSet<>(Arrays.asList(values));
将集合转换为数组:
String[] values = staff.toArray(new String[0]);
6 遗留的集合
6.1 HashTable
HashTable 与 HashMap 类的作用一样,且拥有相同的接口,它本身也是同步的。如果对同步性和遗留代码的兼容性没有任何要求,就应该使用HashMap。如果需要并发访问,则要使用ConcurrentHashMap。
6.2 枚举 Enumeration
6.3 属性映射
6.4 栈 Stack
E stack.push(E item) // 将 item 压入栈并返回 item
E pop() // 弹出并返回栈顶的 item。如果栈为空,请勿调用
E peek() // 返回
6.5 位集 BitSet
BitSet 类提供了一个便于读取、设置或清除各个位的接口。使用这个接口可以避免屏蔽和其他麻烦的位操作。例如,对于一个名为bucketsOfBits的 BitSet:
bucketOfBits.get(i); // 如果第 i 位有设置过,则返回 true
bucketOfBits.set(i); // 将第 i 位设置为 “开” 状态
bucketOfBits.clear(i); // 清除第 i 位
筛法求质数:
package sieve;
import java.util.*;
/**
* This program runs the Sieve of Erathostenes benchmark. It computes all primes up to 2,000,000.
* @version 1.21 2004-08-03
* @author Cay Horstmann
*/
public class Sieve
{
public static void main(String[] s)
{
int n = 2000000;
long start = System.currentTimeMillis();
BitSet b = new BitSet(n + 1);
int count = 0;
int i;
for (i = 2; i <= n; i++)
b.set(i);
i = 2;
while (i * i <= n)
{
if (b.get(i))
{
count++;
int k = 2 * i;
while (k <= n)
{
b.clear(k);
k += i;
}
}
i++;
}
while (i <= n)
{
if (b.get(i)) count++;
i++;
}
long end = System.currentTimeMillis();
System.out.println(count + " primes");
System.out.println((end - start) + " milliseconds");
}
}
------
148933 primes
61 milliseconds
Process finished with exit code 0

