
目录
1. 工作区和 GOPATH
问题:你知道设置
GOPATH有什么意义吗?
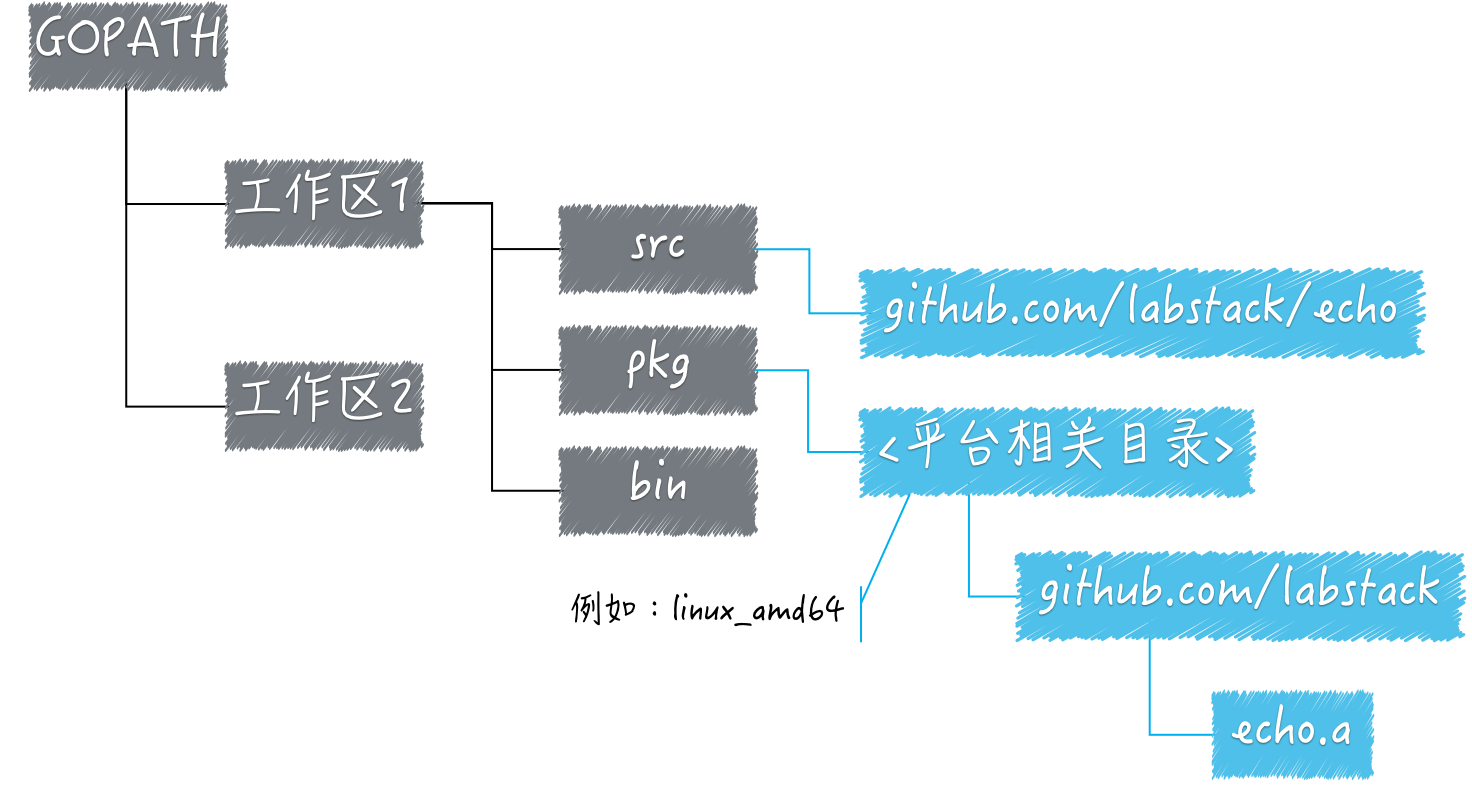
可以把GOPATH简单理解成 Go 语言的工作目录,它的值是一个目录的路径,也可以是多个目录路径,每个目录都代表 Go 语言的一个工作区(workspace)。
我们需要利用这些工作区,来放置 Go 语言的源码文件(source file),以及安装后的归档文件(archieve file,以.a为扩展名的文件)和可执行文件(executable file)。
2. 源码文件的分类
Go 语言中的源码文件可分为三种:
- 命令源码文件
- 库源码文件
- 测试源码文件

2.1 命令源码文件
问题:命令源码文件的用途是什么,怎样编写它?
命令源码文件是程序的运行入口,是每个可独立运行的程序必须拥有的。我们可以通过构建go build或安装go install,生成与其对应的可执行文件,后者一般会与该命令源码文件的直接父目录同名。
如果一个源码文件声明属于main包,并且包含一个无参数声明且无结果声明的main函数,那么它就是命令源码文件:
package main
import "fmt"
func main() {
fmt.Println("Hello, Golang!")
}
对于一个独立的程序来说,命令源码文件永远只会也只能有一个。如果有与命令源码文件同包的源码文件,那么它们也应该声明属于
main包
1. 接收命令行参数
Go 语言标准库中的flag包专门用于接收和解析命令参数,可使用如下语句:
flag.StringVar(&name, "name", "everyone", "The greeting object.")
// 或
var name = flag.String("name", "everyone", "The greeting object.")
函数flag.stringVar接受 4 个参数:
&name:用于存储该命令参数值的地址"name":指定该命令参数的名称"everyone":指定在为追加该命令参数时的默认值"The greeting object.":该命令参数的简短说明,打印命令说明时会用到
package main
import (
"flag"
"fmt"
)
var name string
func init() {
flag.StringVar(&name, "name", "everyone", "The greeting object")
}
func main() {
flag.Parse() // 解析命令参数,并把它们的值赋给相应的变量
fmt.Printf("Hello, %s!\n", name)
}
将上述代码保存为demo1.go,运行以下命令:
go run demo1.go -name="abelsu7"
------
Hello, abelsu7!
查看参数说明:
go run demo1.go --help
------
Usage of C:\Users\abel1\AppData\Local\Temp\go-build617189518\b001\exe\demo1.exe:
-name string
The greeting object (default "everyone")
exit status 2
2. 自定义参数使用说明
有多种方式,最简单的就是对变量flag.Usage重新赋值。flag.Usage的类型是func(),无参数声明也无结果声明。
在flag.Parse()之前加入如下语句:
flag.Usage = func() {
fmt.Fprintf(os.Stderr, "Usage of %s:\n", "question")
flag.PrintDefaults()
}
这样调用go run demo1.go --help后就会输出:
Usage of question:
-name string
The greeting object (default "everyone")
exit status 2
再深入来看,当我们调用flag包中的一些函数时(比如stringVar、Parse等),实际上是在调用flag.CommandLine变量的对应方法。
flag.CommandLine相当于默认情况下的命令参数容器,所以,通过对flag.CommandLine重新赋值,就可以更深层次的定制当前命令源码文件的参数使用说明。
将程序修改为:
package main
import (
"flag"
"fmt"
"os"
)
var name string
func init() {
flag.CommandLine = flag.NewFlagSet("", flag.ExitOnError)
flag.CommandLine.Usage = func() {
fmt.Fprintf(os.Stderr, "Usage of %s:\n", "question")
flag.PrintDefaults()
}
flag.StringVar(&name, "name", "everyone", "The greeting object")
}
func main() {
//flag.Usage = func() {
// fmt.Fprintf(os.Stderr, "Usage of %s:\n", "question")
// flag.PrintDefaults()
//}
flag.Parse()
fmt.Printf("Hello, %s!\n", name)
}
------
> go run demo1.go --help
Usage of question:
-name string
The greeting object (default "everyone")
exit status 2
就会得到一样的输出。而当我们把flag.CommandLine赋值的那条语句改为:
flag.CommandLine = flag.NewFlagSet("", flag.PanicOnError)
再次运行得到:
> go run demo1.go --help
Usage of question:
-name string
The greeting object (default "everyone")
panic: flag: help requested
goroutine 1 [running]:
flag.(*FlagSet).Parse(0xc000084060, 0xc0000443f0, 0x1, 0x1, 0x4, 0x4d0ab5)
C:/Go/src/flag/flag.go:938 +0x107
flag.Parse()
C:/Go/src/flag/flag.go:953 +0x76
main.main()
C:/Users/abel1/go/src/github.com/abelsu7/hello/demo1.go:25 +0x2d
exit status 2
flag.ExitOnError:告诉命令参数容器,当命令后跟--help或者参数设置不正确的时候,在打印命令参数使用说明以后,以exit status 2结束当前程序flag.PanicOnError:区别在于最后会抛出运行时恐慌panic
另外,还可以创建一个私有的命令参数容器,这样就不会影响到全局变量flag.CommandLine:
package main
import (
"flag"
"fmt"
"os"
)
var name string
var cmdLine = flag.NewFlagSet("question", flag.ExitOnError)
func init() {
cmdLine.StringVar(&name, "name", "everyone", "The greeting object")
}
func main() {
cmdLine.Parse(os.Args[1:])
fmt.Printf("Hello, %s!\n", name)
}
------
> go run demo1.go --help
Usage of question:
-name string
The greeting object (default "everyone")
exit status 2
关于
flag包的更多用法可以参考Package flag | golang.google.cn
2.2 库源码文件
库源码文件是不能被直接运行的源码文件,它仅用于存放程序实体,这些程序实体可以被其他代码使用。
在 Go 语言中,程序实体是变量、常量、函数、结构体和接口的统称
程序实体的名字被统称为标识符,它可以是任何 Unicode 编码可以表示的字母字符、数字以及下划线_,但其首字母不能是数字。
首先新建一个_03_demo的包,在该路径下创建命令源码文件demo4.go:
package main
import (
"flag"
)
var name string
func init() {
flag.StringVar(&name, "name", "everyone", "The greeting object.")
}
func main() {
flag.Parse()
hello(name)
}
然后在相同路径下,新建demo4_lib.go:
package main
import "fmt"
func hello(name string) {
fmt.Printf("Hello, %s!\n", name)
}
在{project_path}/_03_demo/路径下,使用以下命令运行程序:
> go run demo4.go demo4_lib.go
Hello, every one!
// 或者
> go build
> _03_demo.exe
Hello, every one!
代码包声明的基本规则
- 同目录下的源码文件的代码包
package声明语句要一致。如果目录中有命令源码文件,那么其他种类的源码文件也应该声明属于main**包,这样才能成功构建和运行 - 源码文件声明的代码包的名称可以与其所在的目录的名称不同。在针对代码包进行构建
go build时,生成的结果文件的主名称与其父目录的名称一致 - 源码文件所在的目录相对于
src目录的相对路径,就是它的代码包导入路径,而实际使用其程序实体时给定的限定符要与它声明所属的代码包名称对应 - 名称的首字母为大写的程序实体才可以被当前包外的代码引用,这样就很自然的把程序实体的访问权限划分为包级私有的和公开的
- 还可以通过创建
internal代码包让一些程序实体仅仅能被当前模块中的其他代码引用。具体规则是,internal代码包中声明的公开程序实体仅能被该代码包的直接父包及其子包中的代码引用。当然,引用前需要先导入internal包。对于其他代码包,导入都是非法的,无法通过编译
3. 变量
Go 语言中的程序实体包括变量、常量、函数、结构体和接口。
Go 语言是静态类型的编程语言,所以在声明变量或常量时,需要指定它们的类型,或者给予足够的信息,这样才能让 Go 语言推导出变量的类型
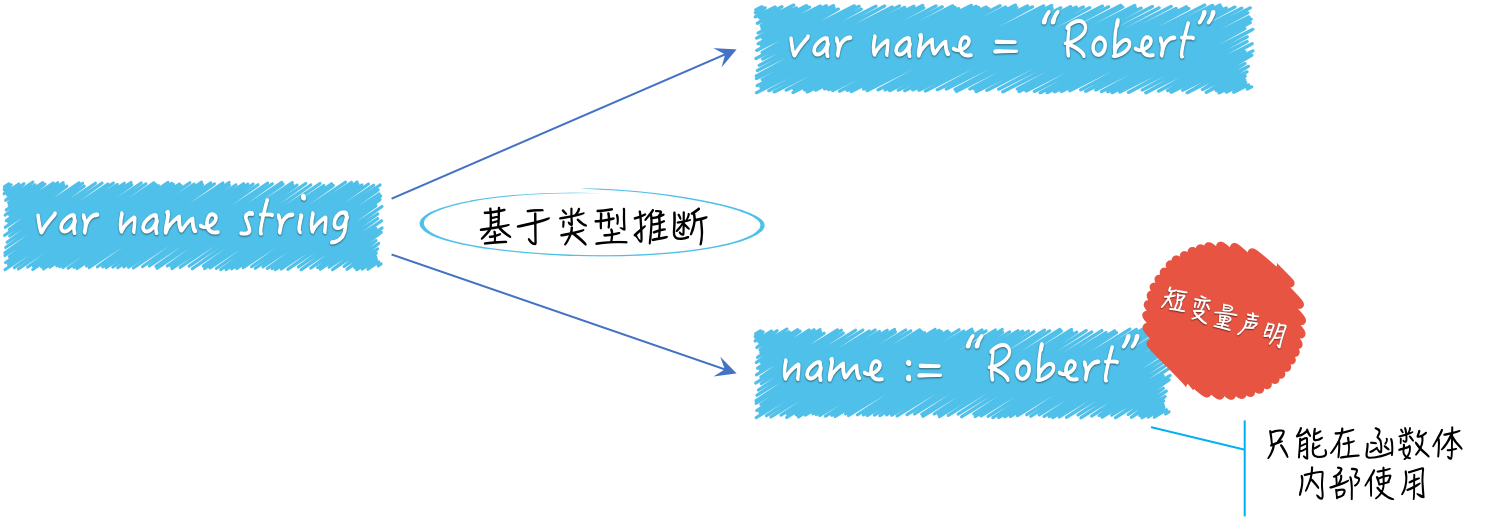
3.1 定义变量的三种方式
package main
import "fmt"
func main() {
var s1 int = 42 // 显式定义,可读性最强
var s2 = 42 // 编译器自动推导变量类型
s3 := 42 // 自动推导类型 + 赋值
fmt.Println(s1, s2, s3)
}
-------------
42 42 42
- 如果一个变量很重要,建议使用第一种显式声明类型的方式来定义,比如全局变量的定义就比较偏好第一种定义方式
- 如果要使用一个不那么重要的局部变量,就可以使用第三种,比如循环下标变量
- 关键字
var无法直接写进循环条件的初始化语句中
问题:Go 语言的类型推断可以带来哪些好处?
除了写代码时可以省略变量类型之外,真正的好处体现在代码重构。
例如下面的代码:
package main
import (
"flag"
"fmt"
)
func main() {
var name = getTheFlag()
flag.Parse()
fmt.Printf("Hello, %v!\n", *name)
}
func getTheFlag() *string {
return flag.String("name", "everyone", "The greeting object.")
}
这样一来,我们可以随意改变getTheFlag函数的内部实现,及其返回结果的类型,而不用修改main函数中的任何代码,这个命令源码文件依然可以通过编译,并成功构建、运行。
通过这种类型推断,可以初步体验动态类型编程语言所带来的一部分优势,即以程序的可维护性和运行效率换来程序灵活性的明显提升。
事实上,Go 语言是静态类型的,所以一旦在初始化变量时确定了它的类型,之后就不可能再改变。这种类型的确定是在编译器完成的,因此不会对程序的运行效率产生任何影响
3.2 旧变量的重声明
var err error
n, err := io.WriteString(os.Stdout, "Hello, everyone!\n")
这里使用短变量声明对新变量n和旧变量err进行了声明并赋值,同时也是对旧变量err的重声明。
3.3 Go 语言基础类型大全
package main
import "fmt"
func main() {
// 有符号整数,可以表示正负
var a int8 = 1 // 1 字节
var b int16 = 2 // 2 字节
var c int32 = 3 // 4 字节
var d int64 = 4 // 8 字节
fmt.Println(a, b, c, d)
// 无符号整数,只能表示非负数
var ua uint8 = 1
var ub uint16 = 2
var uc uint32 = 3
var ud uint64 = 4
fmt.Println(ua, ub, uc, ud)
// int 类型,在32位机器上占4个字节,在64位机器上占8个字节
var e int = 5
var ue uint = 5
fmt.Println(e, ue)
// bool 类型
var f bool = true
fmt.Println(f)
// 字节类型
var j byte = 'a'
fmt.Println(j)
// 字符串类型
var g string = "abcdefg"
fmt.Println(g)
// 浮点数
var h float32 = 3.14
var i float64 = 3.141592653
fmt.Println(h, i)
}
-------------
1 2 3 4
1 2 3 4
5 5
true
abcdefg
3.14 3.141592653
97
3.4 代码块中变量的作用域

3.5 判断一个变量的类型
以下面的代码为例:
package main
import "fmt"
var container = []string{"zero", "one", "two"}
func main() {
container := map[int]string{0: "zero", 1: "one", 2: "two"}
fmt.Printf("The element is %q.\n", container[1])
}
要想在打印其中元素之前,正确判断变量container的类型,则可以使用「类型断言」表达式x.(T):
package main
import "fmt"
var container = []string{"zero", "one", "two"}
func main() {
container := map[int]string{0: "zero", 1: "one", 2: "two"}
value, ok := interface{}(container).(map[int]string)
if ok {
fmt.Println(value[1])
}
fmt.Printf("The element is %q.\n", container[1])
}
------
one
The element is "one".
Process finished with exit code 0
需要注意的是,在类型断言表达式x.(T)中,x代表要被判断类型的值,这个值当下的类型必须是接口类型,所以当container变量类型不是任何的接口类型时,就需要先把它转成某个接口类型的值。

问题:类型转换规则中有哪些值得注意的地方?
在类型转换表达式T(x)中,x可以是一个变量,也可以是一个代表值的字面量(例如1.23和struct{}),还可以是一个表达式。
如果是表达式,那么该表达式的结果只能是一个值,而不能是多个值。如果从源类型到目标类型的转换是不合法的,就会引发一个编译错误。
- 对于整数类型值、整数常量之间的类型转换,原则上只要源值在目标类型的可表示范围内就是合法的
- 虽然直接把一个整数值转换成一个
string类型是可行的,但如果被转换的整数值不是一个有效的 Unicode 代码点,则结果会是�
问题:什么是别名类型?什么是潜在类型?
可以用关键字type声明自定义的各种类型。其中有一种「别名类型」,可以像下面一样声明:
type MyString = string
别名类型与其源类型除了名称不同,其他是完全相同的。例如 Go 语言内建的基本类型中就存在两个别名类型:byte是uint8的别名类型,rune是uint32的别名类型。
而下面没有=的语法被称为对类型的再定义:
type MyString2 string // MyString2 是一个新的类型

对于这里的类型再定义来说,string可以被称为MyString2的潜在类型:即某个类型在本质上是哪个类型,或者是哪个类型的集合。
- 如果两个值潜在类型相同,却属于不同类型,则它们之间是可以进行类型转换的。例如
MyString2与string类型的值,就可以互相转换 - 但对于集合类型
[]MyString2与[]string来说,这样做是不合法的,因为它们的潜在类型不同,分别是MyString2和string
另外,即使两个类型的潜在类型相同,它们的值之间也不能进行判等或比较,它们的变量之间也不能赋值
4. 数组和切片
Go 语言的数组(array)和切片(slice)类型:
- 相同点:都属于集合类的类型,并且,它们的值都可以用来存储某一种类型的值
- 不同点:数组的长度是固定的,而切片是可变长的
数组的长度在声明它时就必须给定,并且之后不会再改变。可以说,数组的长度是其类型的一部分。例如,[1]string和[2]string就是两个不同的数组类型。
而切片的类型字面量中只有元素的类型,没有长度。切片的长度可以自动的随着其中元素数量的增长而增长,但不会随之减少。
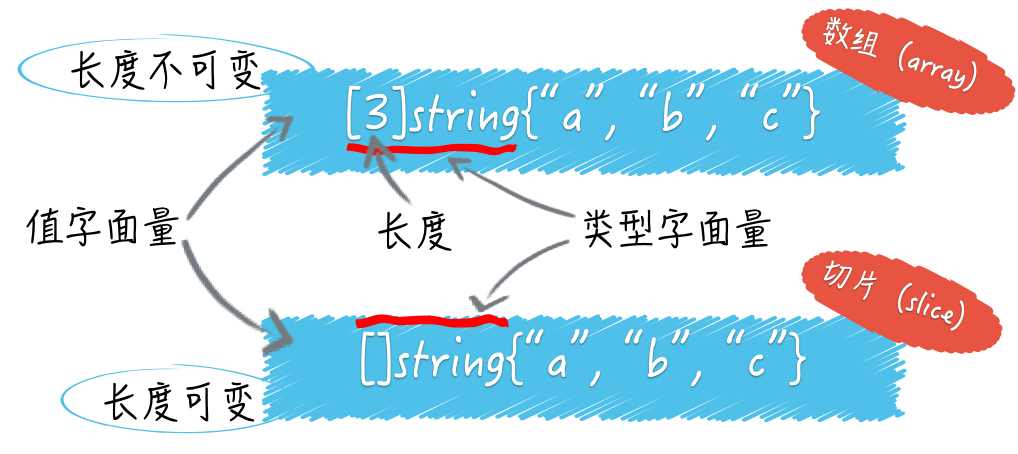
可以把切片看作是对数组的一层简单的封装,因为每个切片都会有一个底层数组,而切片也可以被看作是对数组的某个连续片段的引用。
- Go 语言的切片类型属于引用类型,同属引用类型的还有:字典类型、通道类型、函数类型等
- Go 语言的数组类型则属于值类型,同属值类型的还有:基础数据类型、结构体类型
Go 语言中不存在所谓的“传值还是传引用”的问题。只要看被传递的值的类型就可判断:如果是引用类型,则可看作“传引用”。如果是值类型,则可看作“传值”。从传递成本的角度看,引用类型的值往往比值类型的值低很多
来看一个例子:
s3 := []int{1, 2, 3, 4, 5, 6, 7, 8}
s4 := s3[3:6]
fmt.Printf("The length of s4: %d\n", len(s4))
fmt.Printf("The capacity of s4: %d\n", cap(s4))
fmt.Printf("The value of s4: %d\n", s4)
------
The length of s4: 3
The capacity of s4: 5
The value of s4: [4 5 6]
- 切片表达式中的方括号
s3[3:6]可看作[3,6),这里的3被称为起始索引,6被称为结束索引 - 切片代表的窗口是无法向左扩展的,但可以向右扩展,直至其底层数组的末尾
- 一个切片的容量,可以被看作是透过这个窗口最多可以看到的底层数组中的元素个数
- 切片表达式
s4[0:cap(s4)]的结果值即为把切片的窗口向右扩展到最大
问题:怎样估算切片容量的增长?
一旦一个切片无法容纳更多的元素,Go 语言就会生成一个容量更大的切片(一般情况下容量扩为 2 倍),并将原切片的元素和新元素一并拷贝到新切片中。
但是,当原切片的长度>=1024时候,Go 语言将会以原容量的1.25倍作为新容量的基准,新容量基准会被调整(不断与1.25相乘),直到结果不低于新长度。
另外,如果我们一次追加的元素过多,以至于新长度比原容量的 2 倍还要大,那么新容量就会以新长度为基准。最终的新容量在很多时候都要比新容量基准更大一些。
更多细节可以查看
runtime包中slice.go文件里的growslice及相关函数的具体实现
package main
import "fmt"
func main() {
// 示例1。
s6 := make([]int, 0)
fmt.Printf("The capacity of s6: %d\n", cap(s6))
for i := 1; i <= 5; i++ {
s6 = append(s6, i)
fmt.Printf("s6(%d): len: %d, cap: %d\n", i, len(s6), cap(s6))
}
fmt.Println()
// 示例2。
s7 := make([]int, 1024)
fmt.Printf("The capacity of s7: %d\n", cap(s7))
s7e1 := append(s7, make([]int, 200)...)
fmt.Printf("s7e1: len: %d, cap: %d\n", len(s7e1), cap(s7e1))
s7e2 := append(s7, make([]int, 400)...)
fmt.Printf("s7e2: len: %d, cap: %d\n", len(s7e2), cap(s7e2))
s7e3 := append(s7, make([]int, 600)...)
fmt.Printf("s7e3: len: %d, cap: %d\n", len(s7e3), cap(s7e3))
fmt.Println()
// 示例3。
s8 := make([]int, 10)
fmt.Printf("The capacity of s8: %d\n", cap(s8))
s8a := append(s8, make([]int, 11)...)
fmt.Printf("s8a: len: %d, cap: %d\n", len(s8a), cap(s8a))
s8b := append(s8a, make([]int, 23)...)
fmt.Printf("s8b: len: %d, cap: %d\n", len(s8b), cap(s8b))
s8c := append(s8b, make([]int, 45)...)
fmt.Printf("s8c: len: %d, cap: %d\n", len(s8c), cap(s8c))
}
------
The capacity of s6: 0
s6(1): len: 1, cap: 1
s6(2): len: 2, cap: 2
s6(3): len: 3, cap: 4
s6(4): len: 4, cap: 4
s6(5): len: 5, cap: 8
The capacity of s7: 1024
s7e1: len: 1224, cap: 1280
s7e2: len: 1424, cap: 1696
s7e3: len: 1624, cap: 2048
The capacity of s8: 10
s8a: len: 21, cap: 22
s8b: len: 44, cap: 44
s8c: len: 89, cap: 96
Process finished with exit code 0
问题:切片的底层数组什么时候会被替换?
确切地说,一个切片的底层数组永远也不会被替换。虽然在扩容的时候 Go 语言也会生成新的底层数组,但同时也生成了新的切片。它只是把新的切片作为了新底层数组的窗口,而没有对原切片及其底层数组做任何改动。
在无需扩容时,append函数返回的是指向原底层数组的新切片。而在需要扩容时,append函数返回的是指向新底层数组的新切片。
5. container 包中的容器
5.1 List 链表
Go 语言的链表实现在标准库container/list中,有两个公开的程序实体:List和Element,List实现了一个双向链表,而Element则代表了链表中元素的结构。
package main
import (
"container/list"
"fmt"
)
func main() {
link := list.New()
// 循环插入到头部
for i := 0; i <= 10; i++ {
link.PushBack(i)
}
// 遍历链表
for p := link.Front(); p != link.Back(); p = p.Next() {
fmt.Println("Number", p.Value)
}
}
------
Number 0
Number 1
Number 2
Number 3
Number 4
Number 5
Number 6
Number 7
Number 8
Number 9
Process finished with exit code 0
参考:
5.2 Ring 环
标准库contianer/ring包中的Ring类型实现的是一个循环链表,也就是我们俗称的环。其实List在内部就是一个循环链表,它的根元素永远不会持有任何实际的元素值,而该元素的存在就是为了连接这个循环链表的首尾两端。
List可以作为Queue和Stack的基础数据结构Ring可以用来保存固定数量的元素,例如保存最近 100 万条日志,用户最近 10 次操作等Heap可以用来排序,可用于构造优先级队列
package main;
import (
"container/ring"
"fmt"
)
func printRing(r *ring.Ring) {
r.Do(func(v interface{}) {
fmt.Print(v.(int), " ")
})
fmt.Println()
}
func main() {
//创建环形链表
r := ring.New(5)
//循环赋值
for i := 0; i < 5; i++ {
r.Value = i
//取得下一个元素
r = r.Next()
}
printRing(r)
//环的长度
fmt.Println(r.Len())
//移动环的指针
r.Move(2)
//从当前指针删除n个元素
r.Unlink(2)
printRing(r)
//连接两个环
r2 := ring.New(3)
for i := 0; i < 3; i++ {
r2.Value = i + 10
//取得下一个元素
r2 = r2.Next()
}
printRing(r2)
r.Link(r2)
printRing(r)
}
------
0 1 2 3 4
5
0 3 4
10 11 12
0 10 11 12 3 4
Process finished with exit code 0
5.3 Heap 堆
package main
import (
"container/heap"
"fmt"
)
type IntHeap []int
//我们自定义一个堆需要实现5个接口
//Len(),Less(),Swap()这是继承自sort.Interface
//Push()和Pop()是堆自已的接口
//返回长度
func (h *IntHeap) Len() int {
return len(*h)
}
//比较大小(实现最小堆)
func (h *IntHeap) Less(i, j int) bool {
return (*h)[i] < (*h)[j]
}
//交换值
func (h *IntHeap) Swap(i, j int) {
(*h)[i], (*h)[j] = (*h)[j], (*h)[i]
}
//压入数据
func (h *IntHeap) Push(x interface{}) {
//将数据追加到h中
*h = append(*h, x.(int))
}
//弹出数据
func (h *IntHeap) Pop() interface{} {
old := *h
n := len(old)
x := old[n-1]
//让h指向新的slice
*h = old[0 : n-1]
//返回最后一个元素
return x
}
//打印堆
func (h *IntHeap) PrintHeap() {
//元素的索引号
i := 0
//层级的元素个数
levelCount := 1
for i+1 <= h.Len() {
fmt.Println((*h)[i : i+levelCount])
i += levelCount
if (i + levelCount*2) <= h.Len() {
levelCount *= 2
} else {
levelCount = h.Len() - i
}
}
}
func main() {
a := IntHeap{6, 2, 3, 1, 5, 4}
//初始化堆
heap.Init(&a)
a.PrintHeap()
//弹出数据,保证每次操作都是规范的堆结构
fmt.Println(heap.Pop(&a))
a.PrintHeap()
fmt.Println(heap.Pop(&a))
a.PrintHeap()
heap.Push(&a, 0)
heap.Push(&a, 8)
a.PrintHeap()
}
------
[1]
[2 3]
[6 5 4]
1
[2]
[4 3]
[6 5]
2
[3]
[4 5]
[6]
[0]
[3 5]
[6 4 8]
Process finished with exit code 0
参考:
6. 字典
Go 语言中的字典(map)用来存储键值对的集合,它其实是一个哈希表(Hash Table)的特定实现。Go 语言字典的键类型不可以是函数类型、字典类型和切片类型,键类型的值必须支持判等操作。
7. 通道
Go 语言的通道(channel)类型的值本身就是并发安全的,这也是 Go 语言自带的、唯一一个可以满足并发安全性的类型。
略
8. 函数
在 Go 语言中,函数是一等(first class)公民,函数类型也是一等数据类型。也就是说,函数本身也可以化身为普通的值,在其他函数间传递、赋予变量、做类型判断和转换等:
package main
import "fmt"
type Printer func(contents string) (n int, err error)
func printToStd(contents string) (byteNum int, err error) {
return fmt.Println(contents)
}
func main() {
var p Printer
p = printToStd
p("something")
}
------
something
Process finished with exit code 0
函数签名其实就是函数的参数列表和结果列表的统称,它定义了可用来鉴别不同函数的那些特征,同时也定义了我们与函数交互的方式
只要两个函数的参数列表和结果列表中的元素顺序及其类型是一致的,就可以说它们是实现了同一个函数类型的函数。
因此,在上面的代码中,函数printToStd是函数类型Printer的一个具体实现。
8.1 高阶函数
只要满足下面的任意一个条件,就可以说这个函数是一个高阶函数:
- 接受其他函数作为参数传入
- 把其他函数作为结果返回
8.2 接受其他函数作为参数传入
首先声明一个operate函数类型:
type operate func(x, y int) int
注意:函数类型属于引用类型,它的值可以为
nil
然后编写calculate函数:
func calculate(x int, y int, op operate) (int, error) {
if op == nil {
return 0, errors.New("invalid operation")
}
return op(x, y), nil
}
完整代码如下:
package main
import (
"errors"
"fmt"
)
type operate func(x, y int) int
func sum(x, y int) int {
return x + y
}
func calculate(x int, y int, op operate) (int, error) {
if op == nil {
return 0, errors.New("invalid operation")
}
return op(x, y), nil
}
func main() {
sumResult, _ := calculate(4, 5, sum)
fmt.Println(sumResult)
}
------
9
Process finished with exit code 0
8.3 把其他函数作为结果返回
package main
import (
"errors"
"fmt"
)
type operate func(x, y int) int
// 方案 1
func calculate(x int, y int, op operate) (int, error) {
if op == nil {
return 0, errors.New("invalid operation")
}
return op(x, y), nil
}
// 方案 2
type calculateFunc func(x int, y int) (int, error)
func genCalculator(op operate) calculateFunc {
return func(x int, y int) (int, error) {
if op == nil {
return 0, errors.New("invalid operation")
}
return op(x, y), nil
}
}
func main() {
// 方案 1
x, y := 12, 23
op := func(x, y int) int {
return x + y
}
result, err := calculate(x, y, op)
fmt.Printf("The result: %d (error: %v)\n",
result, err)
result, err = calculate(x, y, nil)
fmt.Printf("The result: %d (error: %v)\n",
result, err)
// 方案 2
x, y = 56, 78
add := genCalculator(op)
result, err = add(x, y)
fmt.Printf("The result: %d (error: %v)\n",
result, err)
}
------
The result: 35 (error: <nil>)
The result: 0 (error: invalid operation)
The result: 134 (error: <nil>)
Process finished with exit code 0
8.4 闭包

8.5 传入参数时区分值类型和引用类型
package main
import "fmt"
func main() {
array1 := [3]string{"a", "b", "c"}
fmt.Printf("The array: %v\n", array1)
array2 := modifyArray(array1)
fmt.Printf("The modified array: %v\n", array2)
fmt.Printf("The original array: %v\n", array1)
}
func modifyArray(a [3]string) [3]string {
a[1] = "x"
return a
}
------
The array: [a b c]
The modified array: [a x c]
The original array: [a b c]
Process finished with exit code 0
- 所有传给函数的参数值都会被复制,函数在其内部使用的并不是参数值的原值,而是它的副本
- 由于数组是值类型,所以每一次复制都会拷贝它,以及它的所有元素值
- 对于引用类型,比如:切片、字典、通道,想下面代码中那样复制它们的值,只会拷贝它们本身而已,并不会拷贝底层数据,即只发生“浅拷贝”
9. 结构体
10. 接口
在 Go 语言的语境中,当我们谈论“接口”的时候,一定是指接口类型,因为接口类型与其他数据类型不同,是没法被实例化的。
具体来讲,就是说我们既不能通过调用new或make函数创建出一个接口类型的值,也无法用字面量来表示一个接口类型的值。
对于任何数据类型,只要它的方法集合中完全包含了一个接口的全部特征(即实现了全部方法),那么它就是这个接口的实现类型。
11. Go 语句及其执行规则
goroutine代表着并发编程模型中的用户级线程。
11.1 进程与线程
进程,描述的是程序的执行过程,是运行着的程序代表,也是资源分配的基本单位。
线程,总是在进程之内,可以被视为进程中运行着的控制流,是调度的基本单位。
- 一个进程至少会包含一个线程。如果一个进程只包含了一个线程,那么它里面的所有代码都只会被串行的执行。每个进程的第一个线程都会随着该进程的启动而被创建,被称为其所属进程的主线程
- 相应的,如果一个进程中包含了多个线程,那么其中的代码就可以被并发的执行。除了主线程之外,其他的线程都是由进程中已存在的线程创建出来的
Go 语言的运行时(runtime)系统会帮助我们自动的创建和销毁系统级的线程,而用户级的线程需要用户自己手动创建和销毁
11.2 调度器
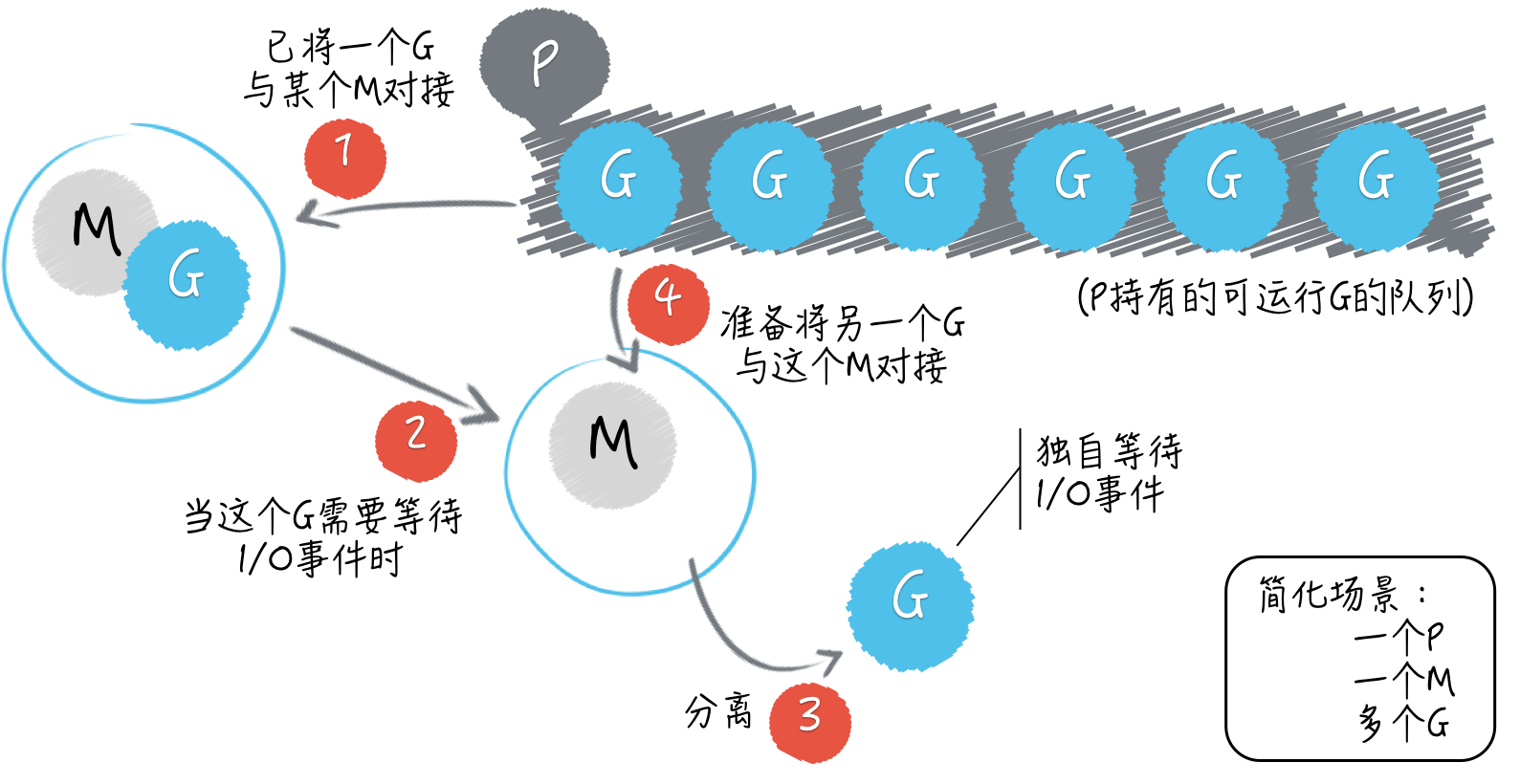
Go 语言不但有独特的并发编程模型,以及用户级线程goroutine,还有提供了一个用于调度goroutine、对接系统级线程的调度器。这个调度器是 Go 语言 runtime 的重要组成部分,它主要负责统筹调配 Go 并发编程模型中的三个主要元素:G(goroutine)、P(processor)、M(machine)。
例如以下代码:
package main
import (
"fmt"
"time"
)
func main() {
for i := 0; i < 10; i++ {
time.Sleep(time.Millisecond)
go func() {
fmt.Println(i)
}()
}
time.Sleep(time.Second)
}
------
1
2
3
4
5
6
7
8
9
10
Process finished with exit code 0
11.3 让主协程等待其他协程
先创建一个通道,长度与我们要手动启用的goroutine数量一致。在每个协程即将运行完毕时,都要向通道发送一个值。
需要注意的是,在通道声明sign := make(chan struct{}, num)中,通道的类型为struct{},其中的类型字面量struct有些类似于空接口类型interface{},它代表了既不包含任何字段也不拥有任何方法的空结构体类型。而它类型值的表示法只有一个,那就是struct{}{}。并且,它占用的内存空间是0字节。
确切的说,
struct{}{}这个值在整个 Go 程序中永远都只会存在一份。虽然我们可以无数次的使用这个值字面量,但用到的却都是同一个值
package main
import (
"fmt"
//"time"
)
func main() {
num := 10
sign := make(chan struct{}, num)
for i := 0; i < num; i++ {
go func() {
fmt.Println(i)
sign <- struct{}{}
}()
}
// 办法 1
//time.Sleep(time.Millisecond * 500)
// 办法 2
for j := 0; j < num; j++ {
<-sign
}
}
------
// 结果不唯一
10
6
3
10
8
10
10
10
10
10
Process finished with exit code 0
使用
sync.WaitGroup会比使用通道更加优雅,之后再来看
11.4 让多个协程按照既定的顺序运行
package main
import (
"fmt"
"sync/atomic"
"time"
)
func main() {
var count uint32
trigger := func(i uint32, fn func()) {
for {
if n := atomic.LoadUint32(&count); n == i {
fn()
atomic.AddUint32(&count, 1)
break
}
time.Sleep(time.Nanosecond)
}
}
for i := uint32(0); i < 10; i++ {
go func(i uint32) {
fn := func() {
fmt.Println(i)
}
trigger(i, fn)
}(i)
}
trigger(10, func() {
fmt.Println("End in main goroutine")
})
}
------
0
1
2
3
4
5
6
7
8
9
End in main goroutine
Process finished with exit code 0
12. 流程控制语句
略
13. 错误处理
13.1 使用 errors 的示例
package main
import (
"errors"
"fmt"
)
func echo(request string) (response string, err error) {
if request == "" {
err = errors.New("empty request")
return
}
response = fmt.Sprintf("echo: %s", request)
return
}
func main() {
for _, req := range []string{"", "hello!"} {
fmt.Printf("request: %s\n", req)
resp, err := echo(req)
if err != nil {
fmt.Printf("error: %s\n", err)
}
fmt.Printf("response: %s\n", resp)
}
}
------
request:
error: empty request
response:
request: hello!
response: echo: hello!
Process finished with exit code 0
13.2 判断错误的具体类型
package main
import (
"fmt"
"os"
"os/exec"
"runtime"
)
// underlyingError 会返回已知的操作系统相关错误的潜在错误值。
func underlyingError(err error) error {
switch err := err.(type) {
case *os.PathError:
return err.Err
case *os.LinkError:
return err.Err
case *os.SyscallError:
return err.Err
case *exec.Error:
return err.Err
}
return err
}
func main() {
// 示例1。
r, w, err := os.Pipe()
if err != nil {
fmt.Printf("unexpected error: %s\n", err)
return
}
// 人为制造 *os.PathError 类型的错误。
r.Close()
_, err = w.Write([]byte("hi"))
uError := underlyingError(err)
fmt.Printf("underlying error: %s (type: %T)\n",
uError, uError)
fmt.Println()
// 示例2。
paths := []string{
os.Args[0], // 当前的源码文件或可执行文件。
"/it/must/not/exist", // 肯定不存在的目录。
os.DevNull, // 肯定存在的目录。
}
printError := func(i int, err error) {
if err == nil {
fmt.Println("nil error")
return
}
err = underlyingError(err)
switch err {
case os.ErrClosed:
fmt.Printf("error(closed)[%d]: %s\n", i, err)
case os.ErrInvalid:
fmt.Printf("error(invalid)[%d]: %s\n", i, err)
case os.ErrPermission:
fmt.Printf("error(permission)[%d]: %s\n", i, err)
}
}
var f *os.File
var index int
{
index = 0
f, err = os.Open(paths[index])
if err != nil {
fmt.Printf("unexpected error: %s\n", err)
return
}
// 人为制造潜在错误为 os.ErrClosed 的错误。
f.Close()
_, err = f.Read([]byte{})
printError(index, err)
}
{
index = 1
// 人为制造 os.ErrInvalid 错误。
f, _ = os.Open(paths[index])
_, err = f.Stat()
printError(index, err)
}
{
index = 2
// 人为制造潜在错误为 os.ErrPermission 的错误。
_, err = exec.LookPath(paths[index])
printError(index, err)
}
if f != nil {
f.Close()
}
fmt.Println()
// 示例3。
paths2 := []string{
runtime.GOROOT(), // 当前环境下的Go语言根目录。
"/it/must/not/exist", // 肯定不存在的目录。
os.DevNull, // 肯定存在的目录。
}
printError2 := func(i int, err error) {
if err == nil {
fmt.Println("nil error")
return
}
err = underlyingError(err)
if os.IsExist(err) {
fmt.Printf("error(exist)[%d]: %s\n", i, err)
} else if os.IsNotExist(err) {
fmt.Printf("error(not exist)[%d]: %s\n", i, err)
} else if os.IsPermission(err) {
fmt.Printf("error(permission)[%d]: %s\n", i, err)
} else {
fmt.Printf("error(other)[%d]: %s\n", i, err)
}
}
{
index = 0
err = os.Mkdir(paths2[index], 0700)
printError2(index, err)
}
{
index = 1
f, err = os.Open(paths[index])
printError2(index, err)
}
{
index = 2
_, err = exec.LookPath(paths[index])
printError2(index, err)
}
if f != nil {
f.Close()
}
}
------
underlying error: The pipe is being closed. (type: syscall.Errno)
error(closed)[0]: file already closed
error(invalid)[1]: invalid argument
nil error
error(exist)[0]: Cannot create a file when that file already exists.
error(not exist)[1]: The system cannot find the path specified.
nil error
Process finished with exit code 0
14. 异常处理
14.1 panic
一个panic的示例如下(在运行时抛出):
panic: runtime error: index out of range
goroutine 1 [running]:
main.main()
/Users/haolin/GeekTime/Golang_Puzzlers/src/puzzlers/article19/q0/demo47.go:5 +0x3d
exit status 2
问题:从
panic被引发到程序终止运行的大致过程是什么?
package main
import (
"fmt"
)
func main() {
fmt.Println("Enter function main.")
caller1()
fmt.Println("Exit function main.")
}
func caller1() {
fmt.Println("Enter function caller1.")
caller2()
fmt.Println("Exit function caller1.")
}
func caller2() {
fmt.Println("Enter function caller2.")
s1 := []int{0, 1, 2, 3, 4}
e5 := s1[5]
_ = e5
fmt.Println("Exit function caller2.")
}
------
Enter function main.
Enter function caller1.
Enter function caller2.
panic: runtime error: index out of range
goroutine 1 [running]:
main.caller2()
C:/Users/abel1/go/src/github.com/abelsu7/hello/main.go:22 +0x69
main.caller1()
C:/Users/abel1/go/src/github.com/abelsu7/hello/main.go:15 +0x6d
main.main()
C:/Users/abel1/go/src/github.com/abelsu7/hello/main.go:9 +0x6d
Process finished with exit code 2
- 当某个函数中的某行代码有意或无意引发了一个
panic,这时,初始的panic详情会被建立起来,并且该程序的控制权会立即从此行代码转移至调用栈的上一级函数,而此行代码所属函数的执行随即终止。 - 紧接着,控制权并不会有任何停留,它又会立即转移至再上一级的调用代码处理,如此一级一级沿着调用栈的反方向传播至顶端,就是我们编写的最外层函数。
- 最后,控制权被 Go 语言运行时系统收回,程序崩溃并终止运行,承载程序这次运行的进程也随之死亡并消失。与此同时,在控制权传播的过程中,
panic详情会被逐渐积累和完善,并会在程序终止之前打印出来。

