



更新中…
目录
- 目录
- 1. 预备知识
- 2. 变量
- 3. 分支与循环
- 4. 数组
- 5. 切片
- 6. 字典
- 7. 字符串
- 8. 结构体
- 9. 接口
- 10. 错误和异常
- 11. 协程
- 12. 通道
- 13. 并发与安全
- 14. 魔术变性指针
- 15. 反射
- 16. 包管理 GOPATH 和 Vendor
1. 预备知识
Go 语言的「元团队」
很多著名的计算机语言都是那么一两个人业余时间捣鼓出来的,但是 Go 语言是 Google 养着一帮团队打造出来的。这个团队非常豪华,它被称之为 Go Team,成员之一就有大名鼎鼎的 Unix 操作系统的创造者 Ken Thompson,C 语言就是他和已经过世的 Dennis Ritchie 一起发明的。

Hello World
package main
import "fmt"
func main() {
fmt.Println("hello world!")
}
直接运行源文件main.go:
> go run main.go
编译二进制文件:
> go build main.go
设置 GOPATH 环境变量
环境变量 GOPATH 指向一个目录,以后我们下载的第三方包和我们自己开发的程序代码包都要放在这个目录里面,它就是 Go 语言的工作目录。
当你在源码里使用import语句导入一个包时,编译器都会来 GOPATH 目录下面寻找这个包。
Mac 和 Linux 用户的 GOPATH 通常设置为~/go。将下面环境变量的设置命令追加到~/.bashrc或~/.zshrc的文件末尾,然后重启终端:
> export GOPATH=~/go
在 Go 语言的早期版本中,还需要用户设置 GOROOT 环境变量,指代 Go 语言开发包的目录,类似于 Java 语言里面的
JAVA_HOME环境变量。不过后来 Go 取消了 GOROOT 的设置,也就是说用户可以不必再操心这个环境变量了,当它不存在就行。
2. 变量
定义变量的三种方式
package main
import "fmt"
func main() {
var s1 int = 42 // 显式定义,可读性最强
var s2 = 42 // 编译器自动推导变量类型
s3 := 42 // 自动推导类型 + 赋值
fmt.Println(s1, s2, s3)
}
-------------
42 42 42
- 如果一个变量很重要,建议使用第一种显式声明类型的方式来定义,比如全局变量的定义就比较偏好第一种定义方式。
- 如果要使用一个不那么重要的局部变量,就可以使用第三种,比如循环下标变量。
var关键字无法直接写进循环条件的初始化语句中。
for i:=0; i<10; i++ {
doSomething()
}
如果在第一种声明变量的时候不赋初值,编译器就会自动赋予相应类型的「零值」,不同类型的零值不尽相同,比如字符串的零值不是nil,而是空串,整型的零值就是0,布尔类型的零值是false。
package main
import "fmt"
func main() {
var i int
fmt.Println(i)
}
-----------
0
全局变量和局部变量
局部变量定义在函数内部,函数调用结束就随之消亡。全局变量则定义在函数外部,在程序运行期间会一直存在。
package main
import "fmt"
var globali int = 24
func main() {
var locali int = 42
fmt.Println(globali, locali)
}
---------------
24 42
- 首字母大写的全局变量:公开的全局变量
- 首字母小写的全局变量:内部的全局变量
内部的全局变量只有当前包内的代码可以访问,外面包的代码是不能看见的。另外,Go 语言没有静态变量。
变量与常量
常量关键字const用来定义常量,可以是全局常量也可以是局部常量,大小写规则与变量一致。常量必须初始化,因为它无法二次赋值。不可以对常量进行修改,否则编译器会报错。
package main
import "fmt"
const globali int = 24
func main() {
const locali int = 42
fmt.Println(globali, locali)
}
---------------
24 42
指针类型
Go 语言被称为互联网时代的 C 语言,它延续使用了 C 语言的指针类型。指针符号*和取地址符&在功能和使用上同 C 语言几乎一模一样。同 C 语言一样,指针还支持二级指针、三级指针,不过在日常应用中很少遇到。
package main
import "fmt"
func main() {
var value int = 42
var p1 *int = &value
var p2 **int = &p1
var p3 ***int = &p2
fmt.Println(p1, p2, p3)
fmt.Println(*p1, **p2, ***p3)
}
----------
0xc4200160a0 0xc42000c028 0xc42000c030
42 42 42
指针变量本质上就是一个整型变量,里面存储的值是另一个变量的内存地址。
*和&符号都只是它的语法糖,是用来在形式上方便使用和理解指针的。*操作符存在两次内存读写,第一次获取指针变量的值,也就是内存地址,然后再去拿这个内存地址所在的变量内容。
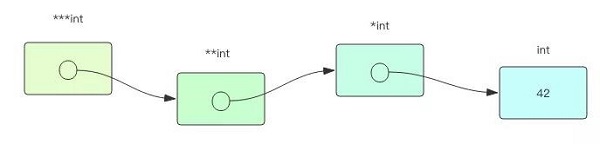
如果普通变量是一个储物箱,那么指针变量就是另一个储物箱,这个储物箱里存放了普通变量所在储物箱的钥匙。通过多级指针来读取变量值就好比在玩一个解密游戏。
Go 语言基础类型大全
package main
import "fmt"
func main() {
// 有符号整数,可以表示正负
var a int8 = 1 // 1 字节
var b int16 = 2 // 2 字节
var c int32 = 3 // 4 字节
var d int64 = 4 // 8 字节
fmt.Println(a, b, c, d)
// 无符号整数,只能表示非负数
var ua uint8 = 1
var ub uint16 = 2
var uc uint32 = 3
var ud uint64 = 4
fmt.Println(ua, ub, uc, ud)
// int 类型,在32位机器上占4个字节,在64位机器上占8个字节
var e int = 5
var ue uint = 5
fmt.Println(e, ue)
// bool 类型
var f bool = true
fmt.Println(f)
// 字节类型
var j byte = 'a'
fmt.Println(j)
// 字符串类型
var g string = "abcdefg"
fmt.Println(g)
// 浮点数
var h float32 = 3.14
var i float64 = 3.141592653
fmt.Println(h, i)
}
-------------
1 2 3 4
1 2 3 4
5 5
true
abcdefg
3.14 3.141592653
97
另外还有几个不太常用的数据类型:
- 复数类型:
complex64和complex128 - Unicode 字符类型:
rune - 指针类型:
uinitptr
3. 分支与循环
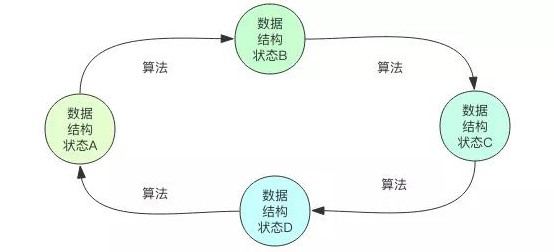
上面的等式并不是什么严格的数学公式,它只是对一般程序的简单认知:
- 数据结构是内存数据关系的静态表示,算法是数据结构从一个状态变化到另一个状态需要执行的机器指令序列;
- 数据结构是静态的,算法是动态的;
- 数据结构是状态,算法是状态的变化。
if else 语句
Go 语言没有三元操作符a > b ? a : b,另外分支与循环语句的条件也不需要用括号括起来。
package main
import "fmt"
func main() {
fmt.Println(sign(max(min(24, 42), max(24, 42))))
}
func max(a int, b int) int {
if a > b {
return a
}
return b
}
func min(a int, b int) int {
if a < b {
return a
}
return b
}
func sign(a int) int {
if a > 0 {
return 1
} else if a < 0 {
return -1
} else {
return 0
}
}
------------
1
switch 语句
switch 语句有两种匹配模式:一种是变量值匹配,另一种是表达式匹配。
package main
import "fmt"
func main() {
fmt.Println(prize1(60))
fmt.Println(prize2(60))
}
// 值匹配
func prize1(score int) string {
switch score / 10 {
case 0, 1, 2, 3, 4, 5:
return "差"
case 6, 7:
return "及格"
case 8:
return "良"
default:
return "优"
}
}
// 表达式匹配
func prize2(score int) string {
// 注意 switch 后面什么也没有
switch {
case score < 60:
return "差"
case score < 80:
return "及格"
case score < 90:
return "良"
default:
return "优"
}
}
for 循环
Go 语言虽然没有提供 while 和 do while 语句,不过这两个语句都可以使用 for 循环的形式来模拟。平时使用 while 语句来写死循环while (true) {},Go 语言可以这么写:
package main
import "fmt"
func main() {
for {
fmt.Println("hello world!")
}
}
或者:
package main
import "fmt"
func main() {
for true {
fmt.Println("hello world!")
}
}
for 什么条件也不带的,相当于 loop 语句。for 带一个条件的,相当于 while 语句。for 带三个条件的就是普通的 for 语句。
package main
import "fmt"
func main() {
for i := 0; i < 10; i++ {
fmt.Println("hello world!")
}
}
循环控制
Go 语言支持 continue 和 break 语句来控制循环,除此之外还支持 goto 语句。
4. 数组
Go 语言里面的数组其实很不常用,这是因为数组是定长静态的,一旦定义好长度就无法更改,而且不同长度的数组属于不同的类型,之间不能相互转换与赋值,用起来多有不便。
切片 (slice) 是动态的数组,是可以扩充内容增加长度的数组。当切片长度不变时,用起来和普通数组一样。当长度不同时,它们也属于相同的类型,之间可以相互赋值。这就决定了数组的应用领域都广泛的被切片取代了。
在切片的底层实现中,数组是切片的基石,是切片的特殊语法隐藏了内部的细节,让用户不能直接看到内部隐藏的数组。可以说切片是数组的一个包装。
数组变量的定义
只声明类型,不赋初值,这时编译器会给数组默认赋上「零值」。
package main
import "fmt"
func main() {
var a [9]int
fmt.Println(a)
}
------------
[0 0 0 0 0 0 0 0 0]
另外三种变量定义形式如下,效果都是一样的的:
package main
import "fmt"
func main() {
var a = [9]int{1, 2, 3, 4, 5, 6, 7, 8, 9}
var b [10]int = [10]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
c := [8]int{1, 2, 3, 4, 5, 6, 7, 8}
fmt.Println(a)
fmt.Println(b)
fmt.Println(c)
}
---------------------
[1 2 3 4 5 6 7 8 9]
[1 2 3 4 5 6 7 8 9 10]
[1 2 3 4 5 6 7 8]
数组的访问
使用下标访问数组中的元素:
package main
import "fmt"
func main() {
var squares [9]int
for i := 0; i < len(squares); i++ {
squares[i] = (i + 1) * (i + 1)
}
fmt.Println(squares)
}
--------------------
[1 4 9 16 25 36 49 64 81]
数组的下标越界检查
Go 语言会对数组访问下标越界进行编译器检查:
package main
import "fmt"
func main() {
var a = [5]int{1,2,3,4,5}
a[101] = 255
fmt.Println(a)
}
-----
./main.go:7:3: invalid array index 101 (out of bounds for 5-element array)
而当数组下标是变量时,Go 会在编译后的代码中插入下标越界检查的逻辑,在运行时也会提示数组下标越界。所以数组的下标访问效率是要打折扣的,比不上 C 语言的数组访问性能。
package main
import "fmt"
func main() {
var a = [5]int{1,2,3,4,5}
var b = 101
a[b] = 255
fmt.Println(a)
}
------------
panic: runtime error: index out of range
goroutine 1 [running]:
main.main()
/Users/qianwp/go/src/github.com/pyloque/practice/main.go:8 +0x3d
exit status 2
数组赋值
同样的子元素类型并且是同样长度的数组才可以相互赋值,否则就是不同的数组类型,不能赋值。数组的赋值本质上是一种浅拷贝操作,赋值的两个数组变量的值不会共享。
package main
import "fmt"
func main() {
var a = [9]int{1, 2, 3, 4, 5, 6, 7, 8, 9}
var b [9]int
b = a
a[0] = 12345
fmt.Println(a)
fmt.Println(b)
}
--------------------------
[12345 2 3 4 5 6 7 8 9]
[1 2 3 4 5 6 7 8 9]
从上面代码的运行结果中可以看出赋值后的两个数组并没有共享内部元素。如果数组的长度很大,那么拷贝操作是有一定的开销的,使用的时候要多加注意。
数组的遍历
数组除了可以使用下标进行遍历之外,还可以使用range关键字来进行遍历。range遍历提供了下面两种形式:
package main
import "fmt"
func main() {
var a = [5]int{1,2,3,4,5}
for index := range a {
fmt.Println(index, a[index])
}
for index, value := range a {
fmt.Println(index, value)
}
}
------------
0 1
1 2
2 3
3 4
4 5
0 1
1 2
2 3
3 4
4 5
5. 切片
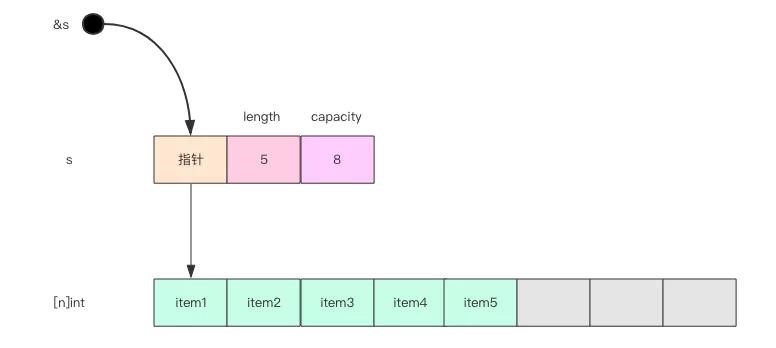
学过 Java 语言的人会比较容易理解切片,因为它的内部结构非常类似于 ArrayList,ArrayList 的内部实现也是一个数组。当数组容量不够需要扩容时,就会换新的数组,还需要将老数组的内容拷贝到新数组。ArrayList 内部有两个非常重要的属性capacity和length。capacity表示内部数组的总长度,length表示当前已经使用的数组的长度。length永远不能超过capacity。
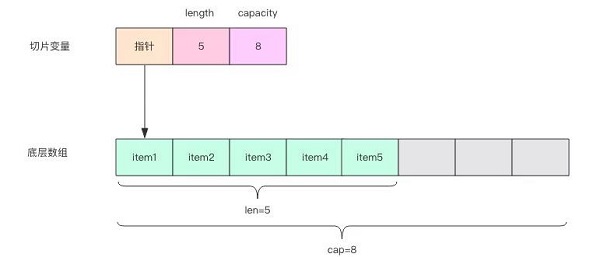
上图中的一个切片变量包含三个域,分别是底层数组的指针、切片的长度length和切片的容量capacity。切片支持 append 操作可以将新内容追加到底层数组,也就是填充上图中的灰色格子。如果格子满了,切片就需要扩容,底层的数组就会更换。
切片的创建
切片的创建有多种方式,先来看最通用的创建方法,那就是内置的 make 函数:
package main
import "fmt"
func main() {
var s1 []int = make([]int, 5, 8)
var s2 []int = make([]int, 8) // 满容切片
fmt.Println(s1)
fmt.Println(s2)
}
-------------
[0 0 0 0 0]
[0 0 0 0 0 0 0 0]
使用 make 函数创建切片,需要提供三个参数:切片的类型、切片的长度和容量。其中第三个参数是可选的,如果不声明切片的容量,那么长度和容量相等,也就是说切片是满容的。
切片和普通变量一样,也可以使用类型自动推导,省区类型定义以及var关键字:
package main
import "fmt"
func main() {
var s1 = make([]int, 5, 8)
s2 := make([]int, 8)
fmt.Println(s1)
fmt.Println(s2)
}
-------------
[0 0 0 0 0]
[0 0 0 0 0 0 0 0]
切片的初始化
使用 make 函数创建的切片内容是「零值切片」,也就是内部数组的元素都是零值。Go 语言还提供了另一种创建切片的语法,允许我们给它赋初值,使用这种方式创建的切片是满容的:
package main
import "fmt"
func main() {
var s []int = []int{1,2,3,4,5} // 满容的
fmt.Println(s, len(s), cap(s))
}
---------
[1 2 3 4 5] 5 5
Go 语言提供了内置函数len()和cap()可以直接获得切片的长度和容量属性。
空切片
在创建切片时,还有两个非常特殊的情况需要考虑,那就是容量和长度都是零的切片,叫做「空切片」。这个不同与之前提到的「零值切片」。
package main
import "fmt"
func main() {
var s1 []int
var s2 []int = []int{}
var s3 []int = make([]int, 0)
fmt.Println(s1, s2, s3)
fmt.Println(len(s1), len(s2), len(s3))
fmt.Println(cap(s1), cap(s2), cap(s3))
}
-----------
[] [] []
0 0 0
0 0 0
上面三种形式创建的切片都是「空切片」,不过在内部结构上这三种形式还是有所差异的,准确来说第一种应该称为「nil 切片」,但是二者形式上几乎一模一样,用起来差不多没有区别,所以初级用户暂时可以不必区分。
切片的赋值
切片的赋值是一次浅拷贝操作,拷贝的是切片变量的三个域。拷贝前后两个变量共享底层数组,对一个切片的修改会影响另一个切片的内容。
package main
import "fmt"
func main() {
var s1 = make([]int, 5, 8)
// 切片的访问和数组差不多
for i := 0; i < len(s1); i++ {
s1[i] = i + 1
}
var s2 = s1
fmt.Println(s1, len(s1), cap(s1))
fmt.Println(s2, len(s2), cap(s2))
// 尝试修改切片内容
s2[0] = 255
fmt.Println(s1)
fmt.Println(s2)
}
--------
[1 2 3 4 5] 5 8
[1 2 3 4 5] 5 8
[255 2 3 4 5]
[255 2 3 4 5]
从上面的输出可以看到赋值的两切片共享了底层数组。
切片的遍历
切片在遍历的语法上和数组是一样的,除了支持下标遍历外,那就是使用 range 关键字。
package main
import "fmt"
func main() {
var s = []int{1,2,3,4,5}
for index := range s {
fmt.Println(index, s[index])
}
for index, value := range s {
fmt.Println(index, value)
}
}
--------
0 1
1 2
2 3
3 4
4 5
0 1
1 2
2 3
3 4
4 5
切片的追加
之前有提到切片是动态的数组,其长度是可以变化的,可以通过追加操作来改变切片的长度。
切片每一次追加后都会形成新的切片变量,如果底层数组没有扩容,那么追加前后的两个切片变量就共享底层数组;如果底层数组扩容了,那么追加前后的底层数组是分离的不共享的。
如果底层数组是共享的,那么一个切片的内容变化就会影响到另一个切片,这点需要特别注意。
package main
import "fmt"
func main() {
var s1 = []int{1,2,3,4,5}
fmt.Println(s1, len(s1), cap(s1))
// 对满容的切片进行追加会分离底层数组
var s2 = append(s1, 6)
fmt.Println(s1, len(s1), cap(s1))
fmt.Println(s2, len(s2), cap(s2))
// 对非满容的切片进行追加会共享底层数组
var s3 = append(s2, 7)
fmt.Println(s2, len(s2), cap(s2))
fmt.Println(s3, len(s3), cap(s3))
}
--------------------------
[1 2 3 4 5] 5 5
[1 2 3 4 5] 5 5
[1 2 3 4 5 6] 6 10
[1 2 3 4 5 6] 6 10
[1 2 3 4 5 6 7] 7 10
正是因为切片追加后是新的切片变量,所以 Go 编译器禁止追加了切片后不使用这个新的切片变量,以避免用户以为追加操作的返回值和原切片变量是同一个变量。
package main
import "fmt"
func main() {
var s1 = []int{1,2,3,4,5}
append(s1, 6)
fmt.Println(s1)
}
--------------
./main.go:7:8: append(s1, 6) evaluated but not used
如果真的不需要使用这个新的变量,可以将 append 的结果赋值给下划线变量_。
下划线变量
_是 Go 语言特殊的内置变量,它就像一个黑洞,可以将任意变量赋值给它,但是却不能读取这个特殊变量。
package main
import "fmt"
func main() {
var s1 = []int{1,2,3,4,5}
_ = append(s1, 6)
fmt.Println(s1)
}
----------
[1 2 3 4 5]
还需要注意的是追加虽然会导致底层数组发生扩容、更换的新的数组,但是旧数组并不会立即被销毁被回收,因为老切片还指向着旧数组。
切片的域是只读的
需要仔细思考
我们刚才说切片的长度是可以变化的,为什么又说切片是只读的呢?这不是矛盾么。这是为了提醒读者注意切片追加后形成了一个新的切片变量,而老的切片变量的三个域其实并不会改变,改变的只是底层的数组。这里说的是切片的「域」是只读的,而不是说切片是只读的。切片的「域」就是组成切片变量的三个部分,分别是底层数组的指针、切片的长度和切片的容量。
切片的切割
切片的切割可以类比字符串的子串,它并不是要把切片割断,而是从母切片中拷贝一个子切片出来,子切片和母切片共享底层数组。
package main
import "fmt"
func main() {
var s1 = []int{1,2,3,4,5,6,7}
// start_index 和 end_index,不包含 end_index
// [start_index, end_index)
var s2 = s1[2:5]
fmt.Println(s1, len(s1), cap(s1))
fmt.Println(s2, len(s2), cap(s2))
}
------------
[1 2 3 4 5 6 7] 7 7
[3 4 5] 3 5
上面的输出需要特别注意的是:既然切割前后共享底层数据,那为什么容量不一样呢?下图可以解释这个问题。
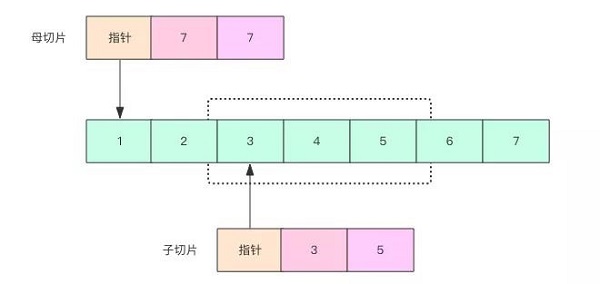
可以注意到子切片的内部数据指针指向了数组的中间位置,而不再是数组的开头了。子切片容量的大小是从中间的位置开始直到切片末尾的长度,母子切片依旧共享底层数组。
子切片语法上要提供起始和结束位置,这两个位置都是可选的。不提供起始位置,默认就是从母切片的初始位置开始(不是底层数组的初始位置)。不提供结束位置,默认就结束到母切片尾部(是长度线,不是容量线)。
package main
import "fmt"
func main() {
var s1 = []int{1, 2, 3, 4, 5, 6, 7}
var s2 = s1[:5]
var s3 = s1[3:]
var s4 = s1[:]
fmt.Println(s1, len(s1), cap(s1))
fmt.Println(s2, len(s2), cap(s2))
fmt.Println(s3, len(s3), cap(s3))
fmt.Println(s4, len(s4), cap(s4))
}
-----------
[1 2 3 4 5 6 7] 7 7
[1 2 3 4 5] 5 7
[4 5 6 7] 4 4
[1 2 3 4 5 6 7] 7 7
上面的s1[:]与普通的切片赋值没有区别,同样是共享底层数组,同样是浅拷贝。另外,Go 语言中切片的下标不支持负数。
数组变切片
对数组进行切割可以转换成切片。切片将原数组作为内部底层数组,也就是说修改了原数组会影响到新切片,对切片的修改也会影响到原数组。
package main
import "fmt"
func main() {
var a = [10]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
var b = a[2:6]
fmt.Println(b)
a[4] = 100
fmt.Println(b)
}
-------
[3 4 5 6]
[3 4 100 6]
copy 函数
Go 语言还内置了一个 copy 函数,用来进行切片的深拷贝。不过其实也没那么深,只是深到底层的数组而已。如果数组里面装的是指针,比如[]*int类型,那么指针指向的内容还是共享的。
func copy(dst, src []T) int
copy 函数不会因为原切片和目标切片的长度问题而额外分配底层数组的内存,它只负责拷贝数组的内容,从原切片拷贝到目标切片,拷贝的量是原切片和目标切片长度的较小值min(len(src), len(dst)),函数返回的是拷贝的实际长度。
package main
import "fmt"
func main() {
var s = make([]int, 5, 8)
for i:=0;i<len(s);i++ {
s[i] = i+1
}
fmt.Println(s)
var d = make([]int, 2, 6)
var n = copy(d, s)
fmt.Println(n, d)
}
-----------
[1 2 3 4 5]
2 [1 2]
切片的扩容点
当比较短的切片扩容时,系统会多分配 100% 的空间,也就是说分配的数组容量是切片长度的 2 倍。但当切片长度超过 1024 时,扩容策略调整为多分配 25% 的空间,这是为了避免空间的过多浪费。
package main
import "fmt"
func main() {
s1 := make([]int, 6)
s2 := make([]int, 1024)
s1 = append(s1, 1)
s2 = append(s2, 2)
fmt.Println(len(s1), cap(s1))
fmt.Println(len(s2), cap(s2))
}
-------------------------------------------
7 12
1025 1344
6. 字典
数组切片让我们具备了可以操作一块连续内存的能力,它是对同质元素的统一管理。而字典则赋予了不连续不同类的内存变量的关联性,它表达的是一种因果关系,字典的 key 是因,字典的 value 是果。
指针、数组切片和字典都是容器型变量。字典比数组切片在使用上要简单很多,但是内部结构却非常复杂。
字典的创建
在创建字典时,必须要给 key 和 value 指定类型。创建字典也可以使用 make 函数:
package main
import "fmt"
func main() {
var m map[int]string = make(map[int]string)
fmt.Println(m, len(m))
}
----------
map[] 0
使用 make 函数创建的字典是空的,长度为零,内部没有任何元素。如果需要给字典提供初始化的元素,就需要使用另一种创建字典的方式:
package main
import "fmt"
func main() {
var m map[int]string = map[int]string{
90: "优秀",
80: "良好",
60: "及格", // 注意这里逗号不可缺少,否则会报语法错误
}
fmt.Println(m, len(m))
}
---------------
map[90:优秀 80:良好 60:及格] 3
字典变量同样支持类型推导,上面的变量定义可以简写成:
var m = map[int]string {
90: "优秀",
80: "良好",
60: "及格",
}
如果提前知道字典内部键值对的数量,那么还可以给 make 函数传递一个整数值,通知运行时提前分配好相应的内存,这样可以避免字典在长大的过程中要经历的多次扩容操作:
var m = make(map[int]string, 16)
字典的读写
字典可以使用中括号[]来读写内部元素,使用 delete 函数来删除元素:
package main
import "fmt"
func main() {
var fruits = map[string]int {
"apple": 2,
"banana": 5,
"orange": 8,
}
// 读取元素
var score = fruits["banana"]
fmt.Println(score)
// 增加或修改元素
fruits["pear"] = 3
fmt.Println(fruits)
// 删除元素
delete(fruits, "pear")
fmt.Println(fruits)
}
-----------------------
5
map[apple:2 banana:5 orange:8 pear:3]
map[orange:8 apple:2 banana:5]
字典 key 不存在会怎么样?
删除操作时,如果对应的 key 不存在,delete 函数会静默处理。读操作时,如果 key 不存在,也不会抛出异常,它会返回 value 类型对应的零值。
可以通过字典的特殊语法来判断对应的 key 是否存在:
package main
import "fmt"
func main() {
var fruits = map[string]int {
"apple": 2,
"banana": 5,
"orange": 8,
}
var score, ok = fruits["durin"]
if ok {
fmt.Println(score)
} else {
fmt.Println("durin not exists")
}
fruits["durin"] = 0
score, ok = fruits["durin"]
if ok {
fmt.Println(score)
} else {
fmt.Println("durin still not exists")
}
}
-------------
durin not exists
0
字典的下标读取可以返回两个值,使用第二个返回值都表示对应的 key 是否存在。它只是 Go 语言提供的语法糖,内部并没有太多的玄妙。
正常的函数调用可以返回多个值,但是并不具备这种“随机应变”的特殊能力 —— 「多态返回值」。
字典的遍历
字典的遍历提供了以下两种方式:一种是需要携带 value,另一种是只需要 key,需要使用到 Go 语言的 range 关键字:
package main
import "fmt"
func main() {
var fruits = map[string]int {
"apple": 2,
"banana": 5,
"orange": 8,
}
for name, score := range fruits {
fmt.Println(name, score)
}
for name := range fruits {
fmt.Println(name)
}
}
------------
orange 8
apple 2
banana 5
apple
banana
orange
然而,Go 语言的字典并没有提供例如keys()或values()这样的方法,意味着如果要获取 key 列表,就得自己循环一下:
package main
import "fmt"
func main() {
var fruits = map[string]int {
"apple": 2,
"banana": 5,
"orange": 8,
}
var names = make([]string, 0, len(fruits))
var scores = make([]int, 0, len(fruits))
for name, score := range fruits {
names = append(names, name)
scores = append(scores, score)
}
fmt.Println(names, scores)
}
----------
[apple banana orange] [2 5 8]
注意:遍历的时候,直接得到的 value 是拷贝过后的,会影响性能。在遍历中,使用
map[key]的方式可以直接用索引获取数据,速度要比使用 value 快将近一倍,但要注意指针安全的问题。
线程安全
Go 语言的内置字典不是线程安全的,如果需要线程安全,必须使用锁来控制。
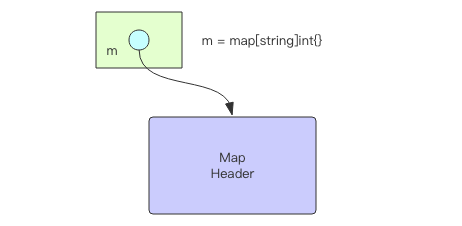
字典变量里存的是什么?
字典变量里存的只是一个地址指针,这个指针指向字典的头部对象。所以字典变量占用的空间是一个字,也就是一个指针的大小,64 位机器是 8 字节,32 位机器是 4 字节。
可以使用 unsafe 包提供的Sizeof函数来计算一个变量的大小:
package main
import (
"fmt"
"unsafe"
)
func main() {
var m = map[string]int{
"apple": 2,
"pear": 3,
"banana": 5,
}
fmt.Println(unsafe.Sizeof(m))
}
------
8
7. 字符串
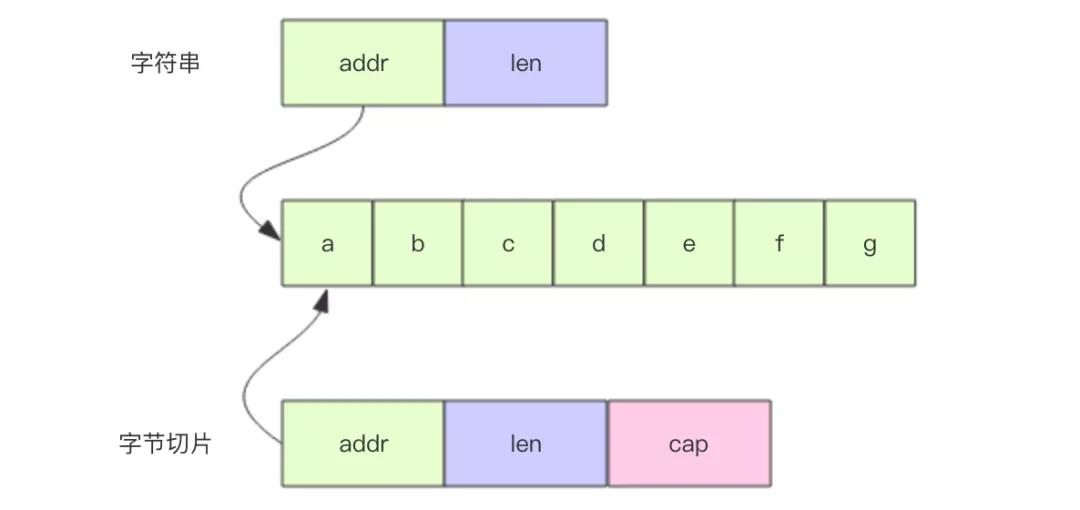
字符串通常有两种设计,一种是「字符」串,一种是「字节」串。「字符」串中的每个字都是定长的,而「字节」串中每个字是不定长的。Go 语言里的字符串是「字节」串,英文字符占用 1 个字节,非英文字符占多个字节。这意味着无法通过位置来快速定位出一个完整的字符来,而必须通过遍历的方式来逐个获取单个字符。
我们所说的字符通常是指 unicode 字符,一个 unicode 字符通常用 4 个字节来表示,对应的 Go 语言中的字符 rune 占 4 个字节。
在 Go 语言的源码中可以看到,rune 类型是一个衍生类型,它在内存里面使用
int32类型的 4 个字节存储。
type rune int32
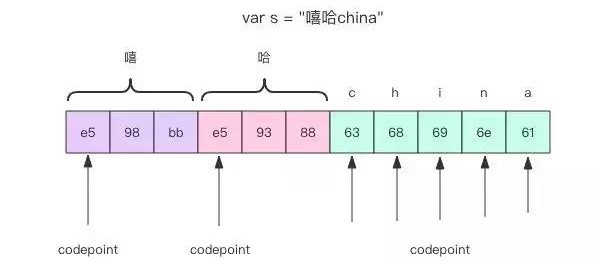
其中 codepoint 是每个「字」的实际偏移量。Go 语言的字符串采用 utf-8 编码,中文汉字通常需要占用 3 个字节,英文只需要 1 个字节。len()函数得到的是字节的数量,通过下标来访问字符串得到的是「字节」。
按字节遍历
字符串可以通过下标来访问内部字节数组具体位置上的字节,字节是 byte 类型:
package main
import "fmt"
func main() {
var s = "嘻哈china"
for i:=0;i<len(s);i++ {
fmt.Printf("%x ", s[i])
}
}
-----------
e5 98 bb e5 93 88 63 68 69 6e 61
按字符 rune 遍历
package main
import "fmt"
func main() {
var s = "嘻哈china"
for codepoint, runeValue := range s {
fmt.Printf("%d %d ", codepoint, int32(runeValue))
}
}
-----------
0 22075 3 21704 6 99 7 104 8 105 9 110 10 97
对字符串进行 range 遍历,每次迭代出两个变量codepoint和runeValue,codepoint 表示字符起始位置,runeValue表示对应的 unicode 编码(类型是 rune)。
字符串的内存表示
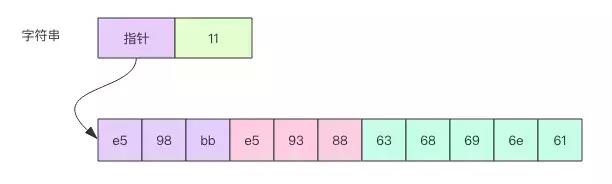
字符串的内存结构不仅包含前面提到的字节数组,编译器还为它分配了头部字段来存储 长度信息 和 指向底层字节数组的指针,如上图所示,结构非常类似于切片,区别是头部少了一个容量字段。
字符串是只读的
可以使用下标来读取字符串指定位置的字节,但是无法修改这个位置上的字节内容。如果尝试使用下标赋值,编译器在语法上直接拒绝:
package main
func main() {
var s = "hello"
s[0] = 'H'
}
--------
./main.go:5:7: cannot assign to s[0]
字符串的切割
字符串在内存形式上比较接近于切片,它也可以像切片一样进行切割来获取子串。子串和母串共享底层字节数组。
package main
import "fmt"
func main() {
var s1 = "hello world"
var s2 = s1[3:8]
fmt.Println(s2)
}
-------
lo wo
字节切片和字符串的相互转换
在使用 Go 语言进行网络编程时,经常需要将来自网络的字节流转换成内存字符串,同时也需要将内存字符串转换成网络字节流。Go 语言直接内置了字节切片和字符串的相互转换语法:
package main
import "fmt"
func main() {
var s1 = "hello world"
var b = []byte(s1) // 字符串转字节切片
var s2 = string(b) // 字节切片转字符串
fmt.Println(b)
fmt.Println(s2)
}
--------
[104 101 108 108 111 32 119 111 114 108 100]
hello world
注意:字节切片和字符串的底层字节数组不是共享的,底层字节数组会被拷贝。这是因为字节切片的底层数组内容是可以修改的,而字符串的底层字节数组是只读的,如果共享了,就会导致字符串的只读属性不再成立。
8. 结构体
Go 语言结构体里面装的是基础类型、数组、切片、字典以及其他类型结构体等。
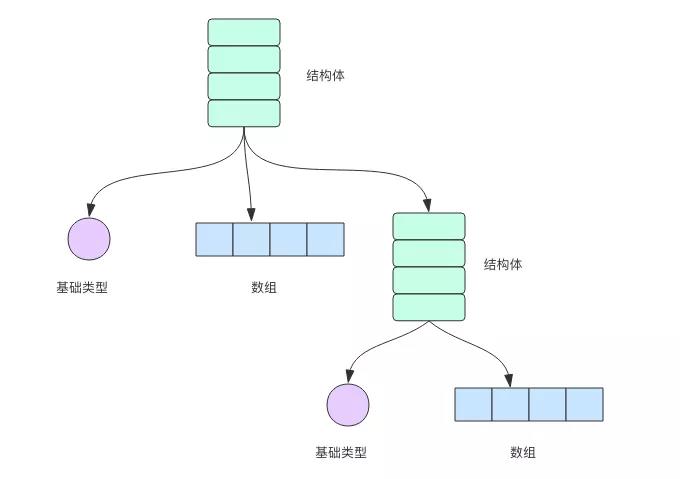
结构体类型的定义
结构体和其它高级语言里的「类」比较相似:
type Circle struct {
x int
y int
Radius int
}
需要特别注意的是结构体内部变量的大小写,首字母大写是公开变量,首字母小写是内部变量,分别相当于类成员变量的 public 和 private 类别。内部变量只有属于同一个 package 的代码才能直接访问。
结构体变量的创建
最常见的创建形式是「KV 形式」,通过显式指定结构体内部字段的名称和初始值来初始化结构体,没有指定初值的字段会自动初始化为相应类型的「零值」:
package main
import "fmt"
type Circle struct {
x int
y int
Radius int
}
func main() {
var c1 Circle = Circle{
x: 100,
y: 100,
Radius: 50,
}
var c2 Circle = Circle{
Radius: 50,
}
var c3 Circle = Circle{}
fmt.Printf("%+v\n", c1)
fmt.Printf("%+v\n", c2)
fmt.Printf("%+v\n", c3)
}
----------
{x:100 y:100 Radius:50}
{x:0 y:0 Radius:50}
{x:0 y:0 Radius:0}
结构体的第二种创建形式是不指定字段名称来顺序字段初始化,需要显式提供所有字段的初值,一个都不能少。这种形式称之为「顺序形式」:
package main
import "fmt"
type Circle struct {
x int
y int
Radius int
}
func main() {
var c Circle = Circle{100, 100, 50}
fmt.Printf("%+v\n", c)
}
-------
{x:100 y:100 Radius:50}
结构体变量和普通变量都有指针形式,使用取地址符&就可以得到结构体的指针类型:
package main
import "fmt"
type Circle struct {
x int
y int
Radius int
}
func main() {
var c *Circle = &Circle{100, 100, 50}
fmt.Printf("%+v\n", c)
}
-----------
&{x:100 y:100 Radius:50}
结构体变量创建的第三种形式是使用全局的new()函数来创建一个「零值」结构体,所有字段都被初始化为相应类型的零值:
package main
import "fmt"
type Circle struct {
x int
y int
Radius int
}
func main() {
var c *Circle = new(Circle)
fmt.Printf("%+v\n", c)
}
----------
&{x:0 y:0 Radius:0}
第四种创建形式也是零值初始化:
package main
import "fmt"
type Circle struct {
x int
y int
Radius int
}
func main() {
var c Circle
fmt.Printf("%+v\n", c)
}
----------
{x:0 y:0 Radius:0}
三种零值初始化形式对比:
var c1 Circle = Circle{}
var c2 Circle
var c3 *Circle = new(Circle)
零值结构体和 nil 结构体
nil 结构体是指结构体指针变量没有指向一个实际存在的内存。这样的指针变量只会占用 1 个指针的存储空间,也就是一个机器字的内存大小。
var c *Circle = nil
而零值结构体则会实际占用内存空间,只不过每个字段都是零值。
结构体的内存大小
Go 语言的 unsafe 包提供了获取结构体内存占用的函数Sizeof():
package main
import "fmt"
import "unsafe"
type Circle struct {
x int
y int
Radius int
}
func main() {
var c Circle = Circle{Radius: 50}
fmt.Println(unsafe.Sizeof(c))
}
-------
24
64 位机器上每个 int 类型都是 8 字节。而 32 位机器上,Circle 结构体就只会占用 12 字节。
结构体的拷贝
结构体之间可以相互赋值,本质上是一次浅拷贝操作,拷贝了结构体内部的所有字段。
结构体指针之间也可以相互赋值,本质上也是一次浅拷贝操作,不过它拷贝的仅仅是指针地址值,结构体的内容是共享的。
package main
import "fmt"
type Circle struct {
x int
y int
Radius int
}
func main() {
var c1 Circle = Circle{Radius: 50}
var c2 Circle = c1
fmt.Printf("%+v\n", c1)
fmt.Printf("%+v\n", c2)
c1.Radius = 100
fmt.Printf("%+v\n", c1)
fmt.Printf("%+v\n", c2)
var c3 *Circle = &Circle{Radius: 50}
var c4 *Circle = c3
fmt.Printf("%+v\n", c3)
fmt.Printf("%+v\n", c4)
c3.Radius = 100
fmt.Printf("%+v\n", c3)
fmt.Printf("%+v\n", c4)
}
----------------------
{x:0 y:0 Radius:50}
{x:0 y:0 Radius:50}
{x:0 y:0 Radius:100}
{x:0 y:0 Radius:50}
&{x:0 y:0 Radius:50}
&{x:0 y:0 Radius:50}
&{x:0 y:0 Radius:100}
&{x:0 y:0 Radius:100}
通过观察 Go 语言的底层源码,可以发现所有的 Go 语言内置的高级数据结构都是由结构体来完成的。
结构体中的数组和切片
之前分析了数组与切片在内存形式上的区别:数组只有「体」,切片除了「体」之外,还有「头」部。切片的头部和内容体是分离的,使用指针关联起来。
package main
import "fmt"
import "unsafe"
type ArrayStruct struct {
value [10]int
}
type SliceStruct struct {
value []int
}
func main() {
var as = ArrayStruct{[...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}}
var ss = SliceStruct{[]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}}
fmt.Println(unsafe.Sizeof(as), unsafe.Sizeof(ss))
}
-------------
80 24
注意代码中的数组初始化使用了[...]语法糖,表示让编译器自动推导数组的长度。
结构体的参数传递
函数调用时参数传递结构体变量,值传递涉及到结构体字段的浅拷贝,指针传递则会共享结构体内容,只拷贝指针地址,规则上和赋值是等价的:
package main
import "fmt"
type Circle struct {
x int
y int
Radius int
}
func expandByValue(c Circle) {
c.Radius *= 2
}
func expandByPointer(c *Circle) {
c.Radius *= 2
}
func main() {
var c = Circle{Radius: 50}
expandByValue(c)
fmt.Println(c)
expandByPointer(&c)
fmt.Println(c)
}
---------
{0 0 50}
{0 0 100}
结构体方法
package main
import (
"fmt"
"math"
)
type Circle struct {
x int
y int
Radius int
}
// 面积
func (c Circle) Area() float64 {
return math.Pi * float64(c.Radius) * float64(c.Radius)
}
// 周长
func (c Circle) Circumference() float64 {
return 2 * math.Pi * float64(c.Radius)
}
func main() {
var c = Circle{Radius: 50}
fmt.Println(c.Area(), c.Circumference())
// 指针变量调用方法形式上是一样的
var pc = &c
fmt.Println(pc.Area(), pc.Circumference())
}
-----------
7853.981633974483 314.1592653589793
7853.981633974483 314.1592653589793
- Go 语言不喜欢类型的隐式转换,所以需要将整型显式转换成浮点型
- Go 语言结构体方法里面也没有
self和this这样的关键字来指代当前的对象 - Go 语言的方法名称也分首字母大小写,它的权限规则和字段一样,首字母大写就是公开方法,首字母小写就是内部方法,只有归属与同一个包的代码才可以访问
- 结构体的值类型和指针类型访问内部字段和方法在形式上是一样的,都是使用句点
.操作符
结构体的指针方法
结构体的值方法无法改变结构体内部状态。例如,使用下面的方法无法扩大 Circle 的半径:
func (c Circle) expand() {
c.Radius *= 2
}
这是因为参数传递是值传递,复制了一份结构体内容。要想修改结构体内部状态,就必须要使用结构体的指针方法:
func (c *Circle) expand() {
c.Radius *= 2
}
通过指针访问内部的字段需要 2 次内存读取操作,第一步是取得指针地址,第二步是读取地址的内容,它比值访问要慢。但是在方法调用时,指针传递可以避免结构体的拷贝操作,结构体比较大时,这种性能的差距就会比较明显。
还有一些特殊的结构体不允许被复制,比如结构体内部包含有锁时,这时就必须使用它的指针形式来定义方法,否则会发生一些莫名其妙的问题。
内嵌结构体
结构体作为一种变量它可以放进另外一个结构体作为一个字段来使用,这种内嵌结构体的形式在 Go 语言里称之为「组合」:
package main
import "fmt"
type Point struct {
x int
y int
}
func (p Point) show() {
fmt.Println(p.x, p.y)
}
type Circle struct {
loc Point
Radius int
}
func main() {
var c = Circle{
loc: Point{
x: 100,
y: 100,
},
Radius: 50,
}
fmt.Printf("%+v\n", c)
fmt.Printf("%+v\n", c.loc)
fmt.Printf("%d %d\n", c.loc.x, c.loc.y)
c.loc.show()
}
----------------
{loc:{x:100 y:100} Radius:50}
{x:100 y:100}
100 100
100 100
匿名内嵌结构体
还有一种特殊的内嵌结构体形式,内嵌的结构体不提供名称。这时外面的结构体将直接继承内嵌结构体所有的内部字段和方法,匿名的结构体字段将会自动获得以结构体类型的名字命名的字段名称:
package main
import "fmt"
type Point struct {
x int
y int
}
func (p Point) show() {
fmt.Println(p.x, p.y)
}
type Circle struct {
Point // 匿名内嵌结构体
Radius int
}
func main() {
var c = Circle{
Point: Point{
x: 100,
y: 100,
},
Radius: 50,
}
fmt.Printf("%+v\n", c)
fmt.Printf("%+v\n", c.Point)
fmt.Printf("%d %d\n", c.x, c.y) // 继承了字段
fmt.Printf("%d %d\n", c.Point.x, c.Point.y)
c.show() // 继承了方法
c.Point.show()
}
-------
{Point:{x:100 y:100} Radius:50}
{x:100 y:100}
100 100
100 100
100 100
100 100
这里的继承仅仅是形式上的语法糖,c.show()转换成二进制代码后和c.Point.show()是等价的,c.x和c.Point.x也是等价的。
Go 语言的结构体没有多态性
Go 语言不是面向对象语言在于它的结构体明确不支持多态,外结构体的方法不能覆盖内部结构体的方法。
多态是指父类定义的方法可以调用子类实现的方法,不同的子类有不同的实现,从而给父类的方法带来了多样的不同行为。
package main
import "fmt"
type Fruit struct{}
func (f Fruit) eat() {
fmt.Println("eat fruit")
}
func (f Fruit) enjoy() {
fmt.Println("smell first")
f.eat()
fmt.Println("clean finally")
}
type Apple struct {
Fruit
}
func (a Apple) eat() {
fmt.Println("eat apple")
}
type Banana struct {
Fruit
}
func (b Banana) eat() {
fmt.Println("eat banana")
}
func main() {
var apple = Apple{}
var banana = Banana{}
apple.enjoy()
banana.enjoy()
}
----------
smell first
eat fruit
clean finally
smell first
eat fruit
clean finally
可以看到,enjoy方法调用的eat方法还是 Fruit 自己的eat方法,它没能被外面的结构体方法覆盖掉,这意味着面向对象的代码习惯不能直接用到 Go 语言中。
9. 接口
接口是一个对象的对外能力的展现,我们使用一个对象时,往往不需要知道一个对象的内部复杂实现,通过它暴露出来的接口,就知道了这个对象具备哪些能力以及如何使用这个能力。
Go 语言的接口类型非常特别,它的作用和 Java 语言的接口一样,但是在形式上有很大的差别。Java 语言需要在类的定义上显式实现了某些接口,才可以说这个类具备了接口定义的能力。但是 Go 语言的接口是隐式的,只要结构体上定义的方法在形式上(名称、参数和返回值)和接口定义的一样,那么这个结构体就自动实现了这个接口,我们就可以使用这个接口变量来指向结构体对象。
package main
import "fmt"
// 可以闻
type Smellable interface {
smell(s string)
}
// 可以吃
type Eatable interface {
eat(s string)
}
// 苹果既可以闻又可以吃
type Apple struct {
name string
}
func (a Apple) smell(s string) {
fmt.Println(s + " can smell")
}
func (a Apple) eat(s string) {
fmt.Println(s + " can eat")
}
// 花只可以闻
type Flower struct {
name string
}
func (f Flower) smell(s string) {
fmt.Println(s + " can smell")
}
func main() {
var s1 Smellable
var s2 Eatable
var apple = Apple{
name: "Apple",
}
var flower = Flower{
name: "Flower",
}
s1 = apple
s1.smell(apple.name)
s1 = flower
s1.smell(flower.name)
s2 = apple
s2.eat(apple.name)
}
--------------------
apple can smell
flower can smell
apple can eat
Apple 结构体同时实现了Smellable和Eatable这两个接口,而 Flower 结构体只实现了Smellable接口。可以看到在 Go 语言中,无需使用类似于 Java 语言的 implements 关键字,结构体和接口就自动产生了关联。
空接口
如果一个接口里面没有定义任何方法,那么它就是空接口,任意结构体都隐式的实现了空接口。
Go 语言为了避免用户重复定义,自己内置了一个名为interface{}的空接口。空接口里没有方法,所以它也不具备任何能力,其作用相当于 Java 的 Object 类型,可以容纳任意对象,是一个万能容器。比如一个字典的 key 是字符串,但是希望 value 可以容纳任意类型的对象,类似于 Java 语言的 Map 类型,这时候就可以使用空接口类型interface{}。
package main
import "fmt"
func main() {
var user = map[string]interface{}{
"age": 30,
"address": "Guangdong Guangzhou",
"married": true,
}
fmt.Println(user)
// 类型转换语法
var age = user["age"].(int)
var address = user["address"].(string)
var married = user["married"].(bool)
fmt.Println(age, address, married)
}
-------------
map[age:30 address:Guangdong Guangzhou married:true]
30 Guangdong Guangzhou true
因为 user 字典变量的类型是map[string]interface{},从这个字典中直接读取得到的 value 类型是interface{},所以需要通过类型转换才能得到期望的变量。
接口变量的本质
可以将 Go 语言中的接口看成一个特殊的容器:这个容器只能容纳一个对象,只有实现了这个接口类型的对象才可以放进去。
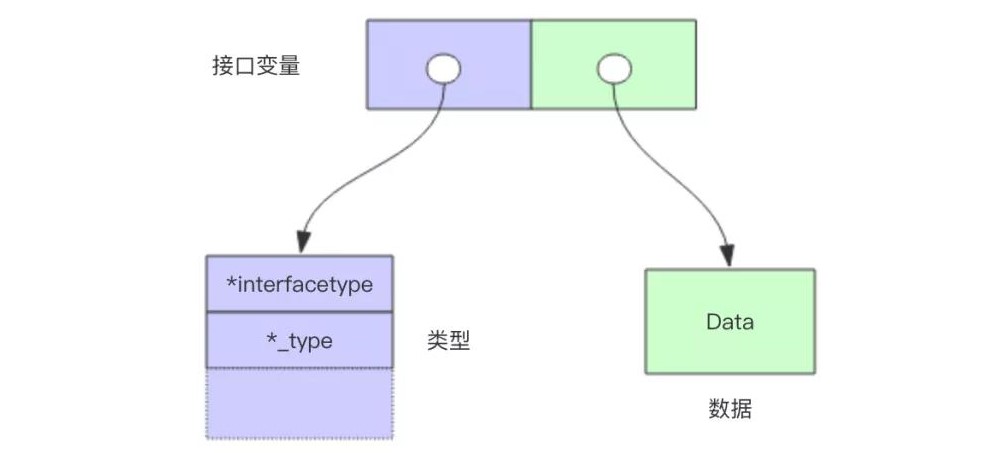
查看 Go 语言的源码发现,接口变量也是由结构体来定义的。这个结构体包含两个指针字段,所以接口变量的内存占用是 2 个机器字:
package main
import "fmt"
import "unsafe"
func main() {
var s interface{}
fmt.Println(unsafe.Sizeof(s))
var arr = [10]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
fmt.Println(unsafe.Sizeof(arr))
s = arr
fmt.Println(unsafe.Sizeof(s))
}
----------
16
80
16
用接口来模拟多态
接口是一种特殊的容器,可以容纳多种不同的对象。那么只要这些对象都同样实现了接口定义的方法,再将容纳的对象替换成另一个对象,就可以模拟实现多态:
package main
import (
"fmt"
)
type Fruitable interface {
eat()
}
type Fruit struct {
Name string // 属性变量
Fruitable // 匿名内嵌接口变量
}
func (f Fruit) want() {
fmt.Printf("I like ")
f.eat() // 外结构体会自动继承匿名内嵌变量的方法
}
type Apple struct{}
func (a Apple) eat() {
fmt.Println("eating apple")
}
type Banana struct{}
func (b Banana) eat() {
fmt.Println("eating banana")
}
func main() {
var f1 = Fruit{"Apple", Apple{}}
var f2 = Fruit{"Banana", Banana{}}
f1.want()
f2.want()
}
---------
I like eating apple
I like eating banana
使用这种方式模拟多态本质上是通过组合属性变量 Name 和接口变量 Fruitable 来做到的。属性变量是对象的数据,而接口变量是对象的功能,将它们组合到一块就形成了一个完整的多态性结构体。
接口的组合继承
接口的定义也支持组合继承:
type Smellable interface {
smell()
}
type Eatable interface {
eat()
}
type Fruitable interface {
Smellable
Eatable
}
这时 Fruitable 接口就自动包含了smell()和eat()两个方法,和下面的定义是等价的:
type Fruitable interface {
smell()
eat()
}
接口变量的赋值
变量的赋值本质上是一次内存浅拷贝:切片的赋值是拷贝了切片头,字符串的赋值是拷贝了字符串的头部,而数组的赋值则是直接拷贝了整个数组。
package main
import "fmt"
type Rect struct {
Width int
Height int
}
func main() {
var a interface{}
var r = Rect{50, 50}
a = r
var rx = a.(Rect)
r.Width = 100
r.Height = 100
fmt.Println(rx)
}
------
{50 50}
可以根据上面的输出结果推断出结构体的内存发生了复制,这是因为赋值a = r和类型转换rx = a.(Rect)两者都发生了数据内存的赋值——浅拷贝。
指向指针的接口变量
将上面的例子改成指针,将接口变量指向结构体指针,就会得到不一样的结果:
package main
import "fmt"
type Rect struct {
Width int
Height int
}
func main() {
var a interface{}
var r = Rect{50, 50}
a = &r // 指向了结构体指针
var rx = a.(*Rect)
r.Width = 100
r.Height = 100
fmt.Println(rx)
}
-------
&{100 100}
可以看到指针变量 rx 指向的内存和变量 r 的内存是同一份,因为在类型转换的过程中只发生了指针变量的内存复制,而指针变量指向的内存是共享的。
10. 错误和异常
错误接口
Go 语言规定凡是实现了错误接口的对象都是错误对象,这个错误接口只定义了一个方法:
type error interface {
Error() string
}
编写一个错误对象很简单:写一个结构体,然后挂在Error方法里:
package main
import "fmt"
type SomeError struct {
Reason string
}
func (s SomeError) Error() string {
return s.Reason
}
func main() {
var err error = SomeError{"something happened"}
fmt.Println(err)
}
---------------
something happened
Go 语言内置了一个通用错误类型,在 errors 包里面。这个包还提供了一个New()函数来方便的创建一个通用错误:
var err = errors.New("something happened")
还可以使用 fmt 包提供的Errorf函数来给错误字符串定制一些参数:
var thing = "something"
var err = fmt.Errorf("%s happened", thing)
错误处理首体验
在 Java 语言中,如果遇到 I/O 问题通常会抛出IOException类型的异常。然而在 Go 语言中,它不会抛出异常,而是以返回值的形式来通知上层逻辑来处理错误。
package main
import (
"fmt"
"os"
)
func main() {
// 打开文件
var f, err = os.Open("quick.go")
if err != nil {
// 文件不存在、权限等原因
fmt.Println("open file failed reason: " + err.Error())
return
}
// 推迟到函数尾调用,确保文件会关闭
defer f.Close()
// 存储文件内容
var content = []byte{}
// 临时的缓冲,按块读取,一次最多读取 100 字节
var buf = make([]byte, 100)
for {
// 读文件,将读到的内容填充到缓冲
n, err := f.Read(buf)
if n > 0 {
// 将读到的内容聚合起来
content = append(content, buf[:n]...)
}
if err != nil {
// 遇到流结束或者其它错误
break
}
}
// 输出文件内容
fmt.Println(string(content))
}
-------
package main
import "os"
import "fmt"
.....
体验 Redis 的错误处理
首先需要使用go get指令下载 redis 包:
go get github.com/go-redis/redis
下面实现一个小功能:获取 Redis 中两个整数值,然后相乘,再存入 Redis 中:
package main
import "fmt"
import "strconv"
import "github.com/go-redis/redis"
func main() {
// 定义客户端对象,内部包含一个连接池
var client = redis.NewClient(&redis.Options{
Addr: "localhost:6379",
})
// 定义三个重要的整数变量值,默认都是零
var val1, val2, val3 int
// 获取第一个值
valstr1, err := client.Get("value1").Result()
if err == nil {
val1, err = strconv.Atoi(valstr1)
if err != nil {
fmt.Println("value1 not a valid integer")
return
}
} else if err != redis.Nil {
fmt.Println("redis access error reason:" + err.Error())
return
}
// 获取第二个值
valstr2, err := client.Get("value2").Result()
if err == nil {
val2, err = strconv.Atoi(valstr2)
if err != nil {
fmt.Println("value1 not a valid integer")
return
}
} else if err != redis.Nil {
fmt.Println("redis access error reason:" + err.Error())
return
}
// 保存第三个值
val3 = val1 * val2
ok, err := client.Set("value3", val3, 0).Result()
if err != nil {
fmt.Println("set value error reason:" + err.Error())
return
}
fmt.Println(ok)
}
------
OK
- Go 语言中不轻易使用异常语句,所以对于任何可能出错的地方都需要判断返回值的错误信息
- 字符串的零值是空串而不是 nil,需要通过返回值的错误信息来判断。
redis.Nil就是客户端专门为 key 不存在这种情况而定义的错误对象
异常与捕捉
Go 语言提供了 panic 和 recover 全局函数让我们可以抛出异常、捕获异常,类似于 try、throw、catch语句,但是又很不一样。比如 panic 函数可以抛出任意对象:
package main
import "fmt"
var negErr = fmt.Errorf("negative number")
func main() {
fmt.Println(fact(5))
fmt.Println(fact(10))
fmt.Println(fact(15))
fmt.Println(fact(-20))
}
func fact(a int) int {
if a <= 0 {
panic(negErr)
}
var result = 1
for i := 1; i <= a; i++ {
result *= i
}
return result
}
-------
120
3628800
1307674368000
panic: negative number
goroutine 1 [running]:
main.fact(0xffffffffffffffec, 0x1)
C:/Users/abel1/go/src/hello/quickgo.go:16 +0x7e
main.main()
C:/Users/abel1/go/src/hello/quickgo.go:11 +0x15e
Process finished with exit code 2
上面的代码抛出了negErr,直接导致了程序崩溃,程序最后打印了异常堆栈信息。下面我们可以使用 recover 函数来保护它,需要结合 defer 语句一起使用,这样可以确保recover()逻辑在程序异常时也可以得到调用:
package main
import "fmt"
var negErr = fmt.Errorf("negative number")
func main() {
defer func() {
if err := recover(); err != nil {
fmt.Println("error catched", err)
}
}()
fmt.Println(fact(5))
fmt.Println(fact(10))
fmt.Println(fact(15))
fmt.Println(fact(-20))
}
func fact(a int) int {
if a <= 0 {
panic(negErr)
}
var result = 1
for i := 1; i <= a; i++ {
result *= i
}
return result
}
-------
120
3628800
1307674368000
error catched negative number
Process finished with exit code 0
可以看到程序成功捕获了异常,并且不再崩溃,但异常点后面的逻辑也不会再继续执行了,
我们经常还需要对recover()返回的结果进行判断,以挑选出我们愿意处理的异常对象类型。对于那些不愿意处理的,可以选择再次抛出,让上层来处理:
defer func() {
if err := recover(); err != nil {
if err == negErr {
fmt.Println("error catched", err)
} else {
panic(err) // rethrow
}
}
}()
Go 语言官方表态不要轻易使用 panic recover,除非你真的无法预料中间可能会发生的错误,或者它能非常显著地简化你的代码。除非逼不得已,否则不要使用它。
多个 defer 语句
有时我们需要在一个函数里使用多次 defer 语句。例如拷贝文件,需要同时打开源文件和目标文件,那就需要调用两次defer f.Close:
package main
import (
"fmt"
"os"
)
func main() {
fsrc, err := os.Open("source.txt")
if err != nil {
fmt.Println("open source file failed")
return
}
defer fsrc.Close()
fdes, err := os.Open("target.txt")
if err != nil {
fmt.Println("open target file failed")
return
}
defer fdes.Close()
fmt.Println("do something here")
}
------
open source file failed
Process finished with exit code 0
需要注意的是 defer 语句的执行顺序和代码编写的顺序是相反的,也就是说最先 defer 的语句最后执行。
package main
import "fmt"
import "os"
func main() {
fsrc, err := os.Open("source.txt")
if err != nil {
fmt.Println("open source file failed")
return
}
defer func() {
fmt.Println("close source file")
fsrc.Close()
}()
fdes, err := os.Open("target.txt")
if err != nil {
fmt.Println("open target file failed")
return
}
defer func() {
fmt.Println("close target file")
fdes.Close()
}()
fmt.Println("do something here")
}
--------
do something here
close target file
close source file
Process finished with exit code 0
11. 协程
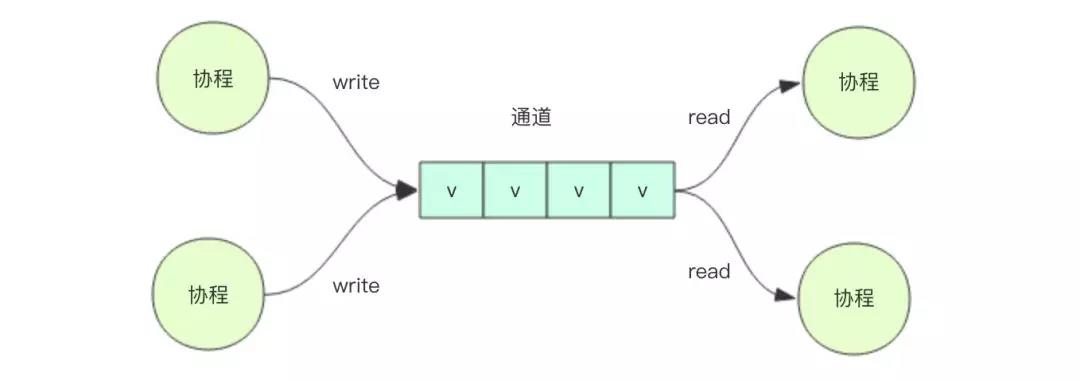
Go 语言里协程被称为goroutine,通道被称为channel。
协程的启动
Go 语言里创建一个协程非常简单:使用go关键词加上一个函数调用就可以了。
Go 语言会启动一个新的协程,函数调用将成为这个协程的入口。
package main
import (
"fmt"
"time"
)
func main() {
fmt.Println("run in main goroutine")
go func() {
fmt.Println("run in child goroutine")
go func() {
fmt.Println("run in grand child goroutine")
go func() {
fmt.Println("run in grand grand child goroutine")
}()
}()
}()
time.Sleep(time.Second)
fmt.Println("main goroutine will quit")
}
------
run in main goroutine
run in child goroutine
run in grand child goroutine
run in grand grand child goroutine
main goroutine will quit
Process finished with exit code 0
在 Go 语言里只有一个主协程,其它都是它的子协程,子协程之间是平行关系。
子协程异常退出
子协程的异常退出会将异常传播到主协程,直接会导致主协程也跟着挂掉,进而导致程序崩溃。
为了保护子协程的安全,通常我们会在协程的入口函数开头增加recover()语句来恢复协程内部发生的异常,阻断它传播到主协程导致程序崩溃:
package main
import (
"fmt"
"time"
)
func main() {
fmt.Println("run in main goroutine")
go func() {
fmt.Println("run in child goroutine")
go func() {
fmt.Println("run in grand child goroutine")
go func() {
fmt.Println("run in grand grand child goroutine")
defer func() {
if err := recover(); err != nil {
// log error
fmt.Println("wtf error happen!")
}
}()
panic("wtf")
}()
}()
}()
time.Sleep(time.Second)
fmt.Println("main goroutine will quit")
}
------
run in main goroutine
run in child goroutine
run in grand child goroutine
run in grand grand child goroutine
wtf error happen!
main goroutine will quit
Process finished with exit code 0
协程的本质
Go 语言中的协程有如下特点:
- 一个进程内部可以运行多个线程,而每个线程又可以运行多个协程
- 线程要负责对协程进行调度,保证每个协程都有机会得到执行
- 当一个协程睡眠时,它要将线程的运行权让给其他协程来运行,而不能持续霸占这个线程
- 同一个线程内部最多只会有一个协程正在运行
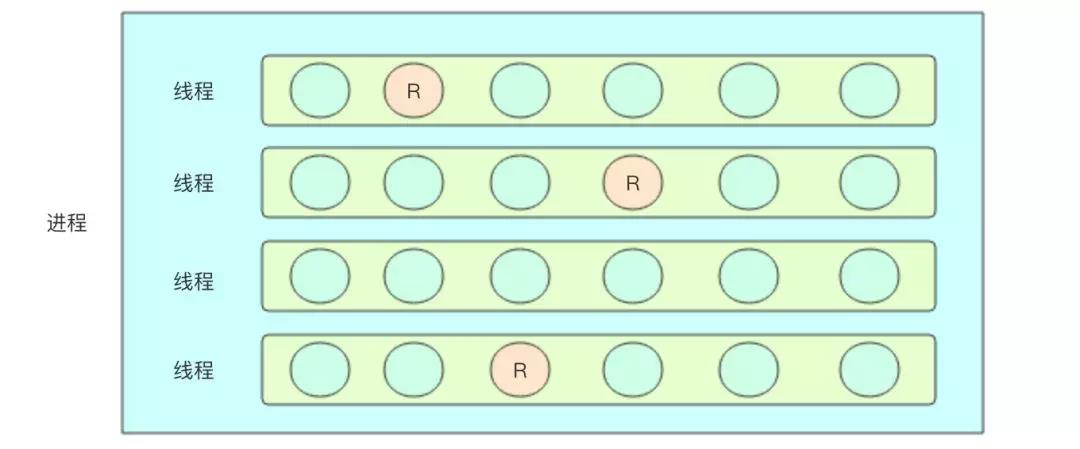
线程的调度是由操作系统负责的,调度算法运行在内核态。而协程的调用是由 Go 语言的运行时负责的,调度算法运行在用户态。
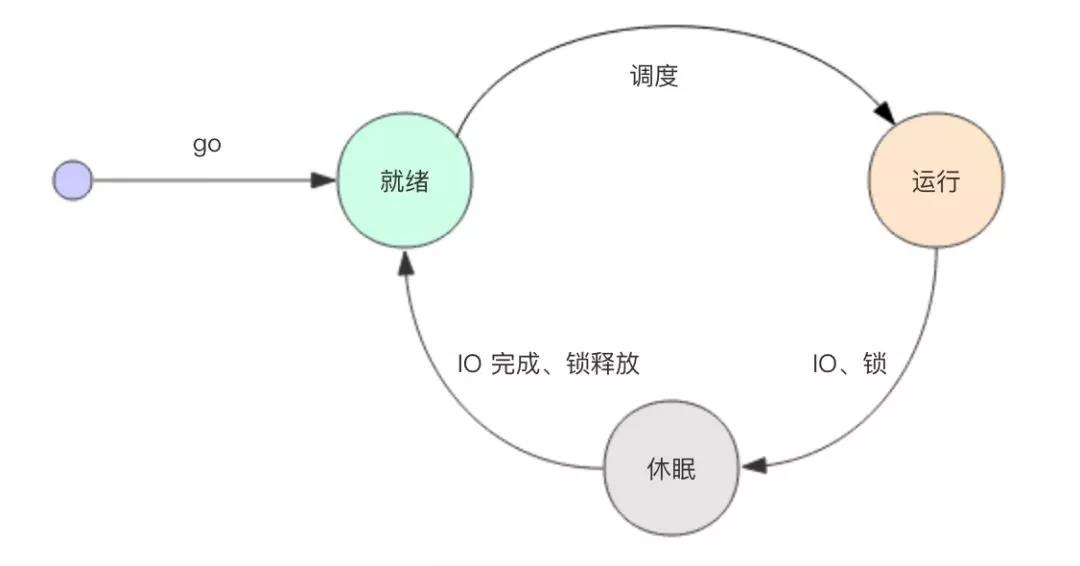
协程可以简化为三种状态:
- 运行态:同一个线程中最多只会存在一个处于运行态的协程
- 就绪态:就绪态的协程是指那些具备了运行能力但是还没有得到运行机会的协程,它们随时会被调度到运行态
- 休眠态:休眠态的协程还不具备运行能力,它们是在等待某些条件的发生,比如 I/O 操作的完成、睡眠时间的结束等
操作系统对线程的调度是抢占式的,也就是说单个线程的死循环不会影响其它线程的执行,每个线程的连续运行受到时间片的限制。
Go 语言运行时对协程的调度并不是抢占式的。如果单个协程通过死循环霸占了线程的执行权,那这个线程就没有机会去运行其它协程了,可以说这个线程假死了。
每个线程都会包含多个就绪态的协程形成了一个就绪队列。Go 语言运行时调度器采用了work-stealing算法,当某个线程空闲时,也就是该线程上所有的协程都在休眠(或者一个协程都没有),它就会去其它线程的就绪队列上去偷一些协程来运行。正常情况下,运行时会尽量平均分配工作任务。
设置线程数
默认情况下,Go 运行时会将线程数会被设置为机器 CPU 逻辑核心数。同时它内置的runtime包提供了GOMAXPROCS(n int)函数允许我们动态调整线程数。
如果参数
n <=0,就不会产生修改效果,等价于读取当前的线程数
package main
import (
"fmt"
"runtime"
)
func main() {
// 读取默认的线程数
fmt.Println(runtime.GOMAXPROCS(0))
// 设置线程数为 10
runtime.GOMAXPROCS(10)
// 读取当前的线程数
fmt.Println(runtime.GOMAXPROCS(0))
}
------
4
10
Process finished with exit code 0
获取当前的协程数量可以使用 runtime 包提供的NumGoroutine()方法:
package main
import (
"fmt"
"runtime"
"time"
)
func main() {
fmt.Println(runtime.NumGoroutine())
for i := 0; i < 10; i++ {
go func() {
for {
time.Sleep(time.Second)
}
}()
}
fmt.Println(runtime.NumGoroutine())
}
------
1
11
Process finished with exit code 0
协程的应用
在日常互联网应用中,Go 语言的协程主要应用在 HTTP API 应用、消息推送系统、聊天系统等。
12. 通道
不同的并行协程之间交流的方式有两种,一种是通过共享变量,另一种是通过队列。
Go 语言鼓励使用队列的形式来交流,它单独为协程之间的队列数据交流定制了特殊的语法——通道。
通道是协程的输入和输出。作为协程的输出,通道是一个容器,它可以容纳数据。作为协程的输入,通道是一个生产者,它可以向协程提供数据。
通道作为容器是有限定大小的,满了就写不进去,空了就读不出来。
通道还有它自己的类型,它可以限定进入通道的数据的类型。
创建通道
创建通道只有一种语法,那就是make全局函数,提供第一个类型参数限定通道可以容纳的数据类型,再提供第二个整数参数作为通道的容器大小。
// 缓冲型通道,里面只能放整数
var bufferedChannel = make(chan int, 1024)
// 非缓冲型通道
var unbufferedChannel = make(chan int)
大小参数是可选的,如果不填,那这个通道的容量为零,叫做「非缓冲型通道」。
非缓冲型通道必须确保有协程正在尝试读取当前通道,否则写操作就会阻塞直到有其它协程来从通道中读东西。
非缓冲型通道总是处于既满又空的状态。与之对应的有限定大小的通道就是缓冲型通道。
在 Go 语言里不存在无界通道,每个通道都是有限定最大容量的
读写通道
Go 语言为通道的读写设计了特殊的箭头语法糖<-,把箭头写在通道变量的右边就是写通道,把箭头写在通道的左边就是读通道。需要注意的是,一次只能读写一个元素。
package main
import "fmt"
func main() {
var ch chan int = make(chan int, 4)
for i := 0; i < cap(ch); i++ {
ch <- i // 写通道
}
for len(ch) > 0 {
fmt.Printf("current len: %d, cap: %d\n", len(ch), cap(ch))
var value int = <-ch // 读通道
fmt.Printf("value: %d\n", value)
}
}
------
current len: 4, cap: 4
value: 0
current len: 3, cap: 4
value: 1
current len: 2, cap: 4
value: 2s
current len: 1, cap: 4
value: 3
Process finished with exit code 0
通道作为容器,可以像切片一样,使用cap()和len()全局函数获得通道的容量和当前内部的元素个数。
通道一般作为不同的协程交流的媒介,不过在同一个协程里也是可以使用的
读写阻塞
通道满了,写操作就会阻塞,协程就会进入睡眠,直到有其它协程读通道挪出了空间,协程才会被唤醒。如果有多个协程的写操作都阻塞了,一个读操作只会唤醒一个协程。
通道空了,读操作就会阻塞,协程也会进入睡眠,直到有其它协程写通道装进了数据才会被唤醒。如果有多个协程的读操作阻塞了,一个写操作也只会唤醒一个协程。
package main
import (
"fmt"
"math/rand"
"time"
)
func send(ch chan int) {
for {
var value = rand.Intn(100)
ch <- value
fmt.Printf("send %d\n", value)
}
}
func recv(ch chan int) {
for {
value := <-ch
fmt.Printf("recv %d\n", value)
time.Sleep(time.Second)
}
}
func main() {
var ch = make(chan int, 1)
// 子协程循环读
go recv(ch)
// 主协程循环写
send(ch)
}
------
send 81
send 87
recv 81
recv 87
send 47
recv 47
send 59
...
关闭通道
Go 语言的通道不但支持读写操作,还支持关闭。读取一个已经关闭的通道会立即返回通道类型的「零值」,而写入一个已经关闭的通道会抛出异常。
如果通道里的元素是整型的,读操作不能通过返回值来确定通道是否关闭
package main
import "fmt"
func main() {
var ch = make(chan int, 4)
ch <- 1
ch <- 2
close(ch)
value := <-ch
fmt.Println(value)
value = <-ch
fmt.Println(value)
value = <-ch
fmt.Println(value)
}
------
1
2
0
Process finished with exit code 0
还可以使用for range语法取代箭头操作符<-来遍历通道。当通道空了,循环会暂停阻塞。当通道关闭时,阻塞停止,循环也跟着结束了。当循环结束时,我们就知道通道已经关闭了。
package main
import "fmt"
func main() {
var ch = make(chan int, 4)
ch <- 1
ch <- 2
close(ch)
// for range 遍历通道
for value := range ch {
fmt.Println(value)
}
}
------
1
2
Process finished with exit code 0
如果将上面关闭通道的语句注释掉,使用for range语法遍历通道就会报错:
package main
import "fmt"
func main() {
var ch = make(chan int, 4)
ch <- 1
ch <- 2
// close(ch)
// for range 遍历通道
for value := range ch {
fmt.Println(value)
}
}
------
1
2
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan receive]:
main.main.func1(0xc00007e000)
C:/Users/abel1/go/src/hello/quickgo.go:13 +0xa1
main.main()
C:/Users/abel1/go/src/hello/quickgo.go:17 +0xa1
Process finished with exit code 2
通道如果没有显式关闭,当它不再被程序使用的时候,会自动关闭被垃圾回收掉。不过优雅的程序应该将通道看成资源,显式关闭每个不再使用的资源是一种良好的习惯
通道写安全
写通道时一定要确保通道没有被关闭,否则会抛出异常:
package main
import "fmt"
// 写通道
func send(ch chan int) {
i := 0
for {
i++
ch <- i
}
}
// 读通道
func recv(ch chan int) {
value := <-ch
fmt.Println(value)
value = <-ch
fmt.Println(value)
close(ch)
}
func main() {
var ch = make(chan int, 4)
go recv(ch)
send(ch)
}
------
1
2
panic: send on closed channel
goroutine 1 [running]:
main.send(0xc00007e000)
C:/Users/abel1/go/src/hello/quickgo.go:10 +0x4b
main.main()
C:/Users/abel1/go/src/hello/quickgo.go:26 +0x6d
Process finished with exit code 2
确保通道写安全的最好方式是由负责写通道的协程自己来关闭通道,读通道的协程不要去关闭通道:
package main
import "fmt"
func send(ch chan int) {
ch <- 1
ch <- 2
ch <- 3
ch <- 4
close(ch)
}
func recv(ch chan int) {
for v := range ch {
fmt.Println(v)
}
}
func main() {
var ch = make(chan int, 1)
go send(ch)
recv(ch)
}
------
1
2
3
4
Process finished with exit code 0
这样可以应对单写多读的场景。不过在多写单读的场景下,任意一个读写通道的协程都不可以随意关闭通道,否则会导致其它写通道协程抛出异常。
这个时候就需要使用内置sync包提供的WaitGroup对象,使用计数来等待指定事件完成,即等待所有的写通道协程都结束运行后才关闭通道:
package main
import (
"fmt"
"sync"
"time"
)
func send(ch chan int, wg *sync.WaitGroup) {
defer wg.Done() // 计数值减 1
i := 0
for i < 4 {
i++
ch <- i
}
}
func recv(ch chan int) {
for value := range ch {
fmt.Println(value)
}
}
func main() {
var ch = make(chan int, 4)
var wg = new(sync.WaitGroup)
wg.Add(2) // 增加计数值
go send(ch, wg) // 写
go send(ch, wg) // 写
go recv(ch)
// Wait() 阻塞等待所有的写通道协程结束
// 待计数值变成零,Wait() 才会返回
wg.Wait()
// 关闭通道
close(ch)
time.Sleep(time.Second)
}
------
1
2
3
4
1
2
3
4
Process finished with exit code 0
多路通道
当消费者有多个消费来源时,只要有一个来源生产了数据,消费者就可以读这个数据进行消费。这时候可以将多个来源通道的数据汇聚到目标通道,然后统一在目标通道进行消费。
package main
import (
"fmt"
"time"
)
// 每隔一段时间产生一个数
func send(ch chan int, gap time.Duration) {
i := 0
for {
i++
ch <- i
time.Sleep(gap)
}
}
// 将多个原通道内容拷贝到单一的目标通道
func collect(source chan int, target chan int) {
for v := range source {
target <- v
}
}
// 从目标通道消费数据
func recv(ch chan int) {
for v := range ch {
fmt.Printf("receive %d\n", v)
}
}
func main() {
var ch1 = make(chan int) // 原通道 1
var ch2 = make(chan int) // 原通道 2
var ch3 = make(chan int) // 目标通道
go send(ch1, time.Second)
go send(ch2, 2*time.Second)
go collect(ch1, ch3)
go collect(ch2, ch3)
recv(ch3)
}
------
receive 1
receive 1
receive 2
receive 2
receive 3
receive 4
receive 3
receive 5
receive 6
receive 4
receive 7
receive 8
receive 5
receive 9
receive 10
receive 6
...
但是这种形式比较繁琐:一来需要单独编写collect()汇聚函数,二来一旦多路通道的规模很大,就需要为每一种消费来源都单独启动一个汇聚协程。好在 Go 语言为这种使用场景提供了「多路复用」语法糖——select语句,它可以同时管理多个通道的读写:如果所有通道都不能读写,它就整体阻塞,只要有一个通道可以读写,它就会继续:
package main
import (
"fmt"
"time"
)
// 每隔一段时间产生一个数
func send(ch chan int, gap time.Duration) {
i := 0
for {
i++
ch <- i
time.Sleep(gap)
}
}
// 从目标通道消费数据
func recv(ch1 chan int, ch2 chan int) {
for {
select {
case v := <-ch1:
fmt.Printf("recv %d from ch1\n", v)
case v := <-ch2:
fmt.Printf("recv %d from ch2\n", v)
}
}
}
func main() {
var ch1 = make(chan int)
var ch2 = make(chan int)
go send(ch1, time.Second)
go send(ch2, time.Second * 2)
recv(ch1, ch2)
}
------
recv 1 from ch2
recv 1 from ch1
recv 2 from ch1
recv 2 from ch2
recv 3 from ch1
recv 4 from ch1
recv 3 from ch2
recv 5 from ch1
recv 6 from ch1
recv 4 from ch2
recv 7 from ch1
...
可以观察到向ch2写数据的生产者go send(ch2, time.Second * 2)要更慢一些。
上面是多路复用select语句的读通道形式,下面是它的写通道形式,只要有一个通道能写进去,它就会打破阻塞:
select {
case ch1 <- v:
fmt.Printf("Send %d to ch1\n", v)
case ch2 <- v:
fmt.Printf("Send %d to ch2\n", v)
}
关于如何在多路复用时关闭通道,可以参考 多路复用 channel 的时候,如何优雅的关闭通道 | Go 语言中文网
非阻塞读写
前面讲的读写都是阻塞读写,Go 语言还提供了通道的非阻塞读写:当通道空时,读操作不会阻塞,当通道满时,写操作也不会阻塞。
非阻塞读写需要依靠select语句的default分支。当select语句所有通道都不可读写时,如果定义了default分支,那就会执行default分支逻辑,这样就起到了不阻塞的效果。
下面演示一个单生产者多消费者的场景。生产者同时向两个通道写数据,写不进去就丢弃:
package main
import (
"fmt"
"time"
)
func send(ch1 chan int, ch2 chan int) {
i := 0
for {
i++
select {
case ch1 <- i:
fmt.Printf("send ch1 %d\n", i)
case ch2 <- i:
fmt.Printf("send ch2 %d\n", i)
default:
}
}
}
func recv(ch chan int, gap time.Duration, name string) {
for v := range ch {
fmt.Printf("receive %s %d\n", name, v)
time.Sleep(gap)
}
}
func main() {
// 无缓冲通道
var ch1 = make(chan int)
var ch2 = make(chan int)
// 两个消费者的休眠时间不一样,名称不一样
go recv(ch1, time.Second, "ch1")
go recv(ch2, time.Second * 2, "ch2")
send(ch1, ch2)
}
------
send ch1 429
send ch2 430
receive ch1 429
receive ch2 430
send ch1 10062541
receive ch1 10062541
send ch2 20457524
receive ch2 20457524
send ch1 20467243
receive ch1 20467243
send ch1 30294965
receive ch1 30294965
send ch2 40021595
receive ch2 40021595
send ch1 40041927
receive ch1 40041927
send ch1 49448528
receive ch1 49448528
send ch2 58807676
receive ch2 58807676
...
可以看到很多数据被丢弃了,消费者读到的数据是不连续的。
将select语句里面的default分支去掉,再运行一次:
send ch2 1
send ch1 2
receive ch1 2
receive ch2 1
receive ch1 3
send ch1 3
receive ch2 4
send ch2 4
receive ch1 5
send ch1 5
receive ch1 6
send ch1 6
receive ch2 7
send ch2 7
receive ch1 8
send ch1 8
receive ch1 9
send ch1 9
receive ch2 10
...
可以看到消费者读到的数据都连续了,写通道又恢复为阻塞的。
select语句的default分支非常关键,它决定了通道读写操作是否阻塞
通道内部结构
Go 语言的通道内部结构是一个循环数组,通过读写偏移量来控制元素发送和接收。它为了保证线程安全,内部会有一个全局锁来控制并发。对于发送和接收操作都会有一个队列来容纳处于阻塞状态的协程。Go 语言中通道的源码位于$GOROOT/src/runtime/chan.go:
type hchan struct {
qcount uint // 通道有效元素个数
dataqsiz uint // 通道容量,循环数组总长度
buf unsafe.Pointer // 数组地址
elemsize uint16 // 内部元素的大小
closed uint32 // 是否已关闭,0 或者 1
elemtype *_type // 内部元素类型信息
sendx uint // 循环数组的写偏移量
recvx uint // 循环数组的读偏移量
recvq waitq // 阻塞在读操作上的协程队列
sendq waitq // 阻塞在写操作上的协程队列
// lock protects all fields in hchan, as well as several
// fields in sudogs blocked on this channel.
//
// Do not change another G's status while holding this lock
// (in particular, do not ready a G), as this can deadlock
// with stack shrinking.
lock mutex // 全局锁
}
这个循环队列和 Java 语言内置的ArrayBlockingQueue结构如出一辙,所以可以从这个数据结构中得出结论:队列在本质上是使用共享变量加锁的方式来实现的,共享变量才是并行交流的本质。
13. 并发与安全
并发编程不同的协程共享数据的方式除了通道之外还有就是共享变量。虽然 Go 语言官方推荐使用通道的方式来共享数据,但是通过变量来共享才是基础,因为通道在底层也是通过共享变量的方式来实现的。通道的内部数据结构包含一个数组,对通道的读写就是对内部数组的读写。
并发环境下共享读写变量必须使用锁来控制数据结构的安全。Go 语言内置了sync包,里面包含了我们平时需要经常使用的互斥锁对象sync.Nutex。
Go 语言内置的字典不是线程安全的,可以使用互斥锁对象来保护字典,让它变成线程安全的
线程不安全的字典
Go 语言从
1.9版本之后自带线程安全的字典sync.map,主要操作有:Store、LoadOrStore、Load、Delete、Range
Go 语言内置了数据结构「竞态检查」工具来帮我们检查程序中是否存在线程不安全的代码。关于 Go 语言的竞态检测器,可以参考 Go 的竞态检测器 | Go 语言中文网。例如下面这段代码:
package main
import "fmt"
func write(d map[string]int) {
d["fruit"] = 2
}
func read(d map[string]int) {
fmt.Println(d["fruit"])
}
func main() {
d := map[string]int{}
go read(d)
write(d)
}
读、写分别是两个协程,存在明显的安全隐患,运行竞态检查指令go run -race quickgo.go观察输出结果:
C:\Users\abel1\go\src\hello>go run -race quickgo.go
==================
WARNING: DATA RACE
Read at 0x00c000052240 by goroutine 6:
runtime.mapaccess1_faststr()
C:/Go/src/runtime/map_faststr.go:12 +0x0
main.read()
C:/Users/abel1/go/src/hello/quickgo.go:10 +0x64
Previous write at 0x00c000052240 by main goroutine:
runtime.mapassign_faststr()
C:/Go/src/runtime/map_faststr.go:190 +0x0
main.main()
C:/Users/abel1/go/src/hello/quickgo.go:6 +0x8f
Goroutine 6 (running) created at:
main.main()
C:/Users/abel1/go/src/hello/quickgo.go:15 +0x60
==================
==================
WARNING: DATA RACE
Read at 0x00c0000422f8 by goroutine 6:
main.read()
C:/Users/abel1/go/src/hello/quickgo.go:10 +0x77
Previous write at 0x00c0000422f8 by main goroutine:
main.main()
C:/Users/abel1/go/src/hello/quickgo.go:6 +0xa4
Goroutine 6 (running) created at:
main.main()
C:/Users/abel1/go/src/hello/quickgo.go:15 +0x60
==================
2
Found 2 data race(s)
exit status 66
竞态检查工具是基于运行时代码检查,而不是通过代码静态分析来完成的。这意味着那些没有机会运行到的代码逻辑中如果存在安全隐患,它是检查不出来的。
线程安全的字典
让字典变的线程安全,就需要使用互斥锁对字典的所有读写操作进行保护:
package main
import (
"fmt"
"sync"
"time"
)
type SafeDict struct {
data map[string]int
mutex *sync.Mutex
}
func NewSafeDict(data map[string]int) *SafeDict {
return &SafeDict{
data: data,
mutex: &sync.Mutex{},
}
}
func (d *SafeDict) Len() int {
d.mutex.Lock()
defer d.mutex.Unlock()
return len(d.data)
}
func (d *SafeDict) Put(key string, value int) (int, bool) {
d.mutex.Lock()
defer d.mutex.Unlock()
old_value, ok := d.data[key]
d.data[key] = value
return old_value, ok
}
func (d *SafeDict) Get(key string) (int, bool) {
d.mutex.Lock()
defer d.mutex.Unlock()
old_value, ok := d.data[key]
return old_value, ok
}
func (d *SafeDict) Delete(key string) (int, bool) {
d.mutex.Lock()
defer d.mutex.Unlock()
old_value, ok := d.data[key]
if ok {
delete(d.data, key)
}
return old_value, ok
}
func write(d *SafeDict, key string, value int) {
d.Put(key, value)
}
func read(d *SafeDict, key string) {
fmt.Println(d.Get(key))
}
func main() {
d := NewSafeDict(map[string]int{
"apple": 2,
"peach": 3,
})
go read(d, "peach")
write(d, "peach", 10)
time.Sleep(time.Second)
}
------
10 true
Process finished with exit code 0
再次使用竞态检查工具运行上面的代码,发现没有之前的警告输出,说明Get()和Put()方法已经做到了协程安全,但是还不能说明Delete()方法是否安全,因为它没有机会得到运行。
避免锁复制
需要注意的是,sync.Mutex是一个结构体对象,这个对象在使用的过程中要避免被复制(浅拷贝)。复制将会导致锁被「分裂」了,起不到保护的作用。所以在平时的使用中要尽量使用它的指针类型。
使用匿名锁字段
我们知道外部结构体可以自动继承匿名内部结构体的所有方法。如果将锁字段匿名,就可以简化代码:
package main
import "fmt"
import "sync"
type SafeDict struct {
data map[string]int
*sync.Mutex
}
func NewSafeDict(data map[string]int) *SafeDict {
return &SafeDict{data, &sync.Mutex{}}
}
func (d *SafeDict) Len() int {
d.Lock()
defer d.Unlock()
return len(d.data)
}
func (d *SafeDict) Put(key string, value int) (int, bool) {
d.Lock()
defer d.Unlock()
old_value, ok := d.data[key]
d.data[key] = value
return old_value, ok
}
func (d *SafeDict) Get(key string) (int, bool) {
d.Lock()
defer d.Unlock()
old_value, ok := d.data[key]
return old_value, ok
}
func (d *SafeDict) Delete(key string) (int, bool) {
d.Lock()
defer d.Unlock()
old_value, ok := d.data[key]
if ok {
delete(d.data, key)
}
return old_value, ok
}
func write(d *SafeDict) {
d.Put("banana", 5)
}
func read(d *SafeDict) {
fmt.Println(d.Get("banana"))
}
func main() {
d := NewSafeDict(map[string]int{
"apple": 2,
"pear": 3,
})
go read(d)
write(d)
}
使用读写锁
日常应用中,大多数并发数据结构都是读多写少的,对于读多写少的场合,可以将互斥锁换成读写锁,可以有效提升性能。读写锁sync.RWMutex提供了四个常用方法,分别是:写加锁Lock()、写释放锁Unlock()、读加锁RLock()和读释放锁RUnlock()。
写锁是排他锁,加写锁时会阻塞其它协程再加读锁和写锁。读锁是共享锁,加读锁还可以允许其它协程再加读锁,但是会阻塞加写锁。另外,读写锁在写并发高的情况下性能退化为普通的互斥锁
将上面代码中SafeDict的互斥锁改造成读写锁:
package main
import "fmt"
import "sync"
type SafeDict struct {
data map[string]int
*sync.RWMutex
}
func NewSafeDict(data map[string]int) *SafeDict {
return &SafeDict{data, &sync.RWMutex{}}
}
func (d *SafeDict) Len() int {
d.RLock()
defer d.RUnlock()
return len(d.data)
}
func (d *SafeDict) Put(key string, value int) (int, bool) {
d.Lock()
defer d.Unlock()
old_value, ok := d.data[key]
d.data[key] = value
return old_value, ok
}
func (d *SafeDict) Get(key string) (int, bool) {
d.RLock()
defer d.RUnlock()
old_value, ok := d.data[key]
return old_value, ok
}
func (d *SafeDict) Delete(key string) (int, bool) {
d.Lock()
defer d.Unlock()
old_value, ok := d.data[key]
if ok {
delete(d.data, key)
}
return old_value, ok
}
func write(d *SafeDict) {
d.Put("banana", 5)
}
func read(d *SafeDict) {
fmt.Println(d.Get("banana"))
}
func main() {
d := NewSafeDict(map[string]int{
"apple": 2,
"pear": 3,
})
go read(d)
write(d)
}
14. 魔术变性指针
使用 Go 语言内置的unsafe包可以直接操纵指定内存地址的内存。
unsafe.Pointer
Pointer代表着变量的内存地址,可以将任意变量的地址转换成Pointer类型,也可以将Pointer类型转换成任意的指针类型,它是不同指针类型之间互转的中间类型。另外,Pointer本身也是一个整型的值。
type Pointer int

指针的加减运算
在 Go 语言中,编译器禁止Pointer类型直接进行加减运算。如果要进行运算,需要将Pointer类型转换为uintptr类型进行加减,然后再将uintptr转换成Pointer类型。uintptr其实也是一个整型:
type uintptr int

package main
import (
"fmt"
"unsafe"
)
type Rect struct {
Width int
Height int
}
func main() {
var r = Rect{50, 50}
// *Rect => Pointer => *int => int
var width = *(*int)(unsafe.Pointer(&r))
// *Rect => Pointer => uintptr => Pointer => *int => int
var height = *(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&r)) + uintptr(8)))
fmt.Println(width, height)
}
------
50 50
Process finished with exit code 0
上面的代码使用unsafe包来读取结构体的内容,下面尝试修改结构体的值:
package main
import (
"fmt"
"unsafe"
)
type Rect struct {
Width int
Height int
}
func main() {
var r = Rect{50, 50}
// *Rect => Pointer => *int => int
var pwidth = (*int)(unsafe.Pointer(&r))
// *Rect => Pointer => uintptr => Pointer => *int => int
var pheight = (*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&r)) + unsafe.Offsetof(r.Height)))
*pwidth = 100
*pheight = 200
fmt.Println(r.Width, r.Height)
}
------
100 200
Process finished with exit code 0
注意可以使用unsafe.Offsetof(r.Height)替换uintptr(8),直接得到字段在结构体内的偏移量。
切片的内部结构
Go 语言的切片分为切片头和内部数组两部分,使用unsafe包来验证一下切片的内部数据结构:
package main
import "fmt"
import "unsafe"
func main() {
// head = {address, 10, 10}
// body = [1,2,3,4,5,6,7,8,9,10]
var s = []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
var address = (**[10]int)(unsafe.Pointer(&s))
var len = (*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&s)) + uintptr(8)))
var cap = (*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&s)) + uintptr(16)))
fmt.Println(address, *len, *cap)
var body = **address
for i := 0; i < *len; i++ {
fmt.Printf("%d ", body[i])
}
}
------
0xc000044400 10 10
1 2 3 4 5 6 7 8 9 10
Process finished with exit code 0
需要注意的是address是一个二级指针变量:
字符串与切片的高效转换
字节切片和字符串之间的转换需要复制内存,而unsafe包则提供了另一种高效的转换方法,让转换前后的字符串和字节切片共享内部存储:
字符串和字节切片的不同点在于头部,字符串的头部 2 个
int字节,切片的头部 3 个int字节
package main
import "fmt"
import "unsafe"
func main() {
fmt.Println(bytes2str(str2bytes("hello")))
}
func str2bytes(s string) []byte {
var strhead = *(*[2]int)(unsafe.Pointer(&s))
var slicehead [3]int
slicehead[0] = strhead[0]
slicehead[1] = strhead[1]
slicehead[2] = strhead[1]
return *(*[]byte)(unsafe.Pointer(&slicehead))
}
func bytes2str(bs []byte) string {
return *(*string)(unsafe.Pointer(&bs))
}
------
hello
Process finished with exit code 0
注意:通过这种方式转换得到的字节切片切记不能修改,因为其底层字节数组是共享的,修改会破坏字符串的只读规则。另外只可以用作临时的局部变量,因为被共享的字节数组随时可能会被回收
深入接口变量的赋值
可参考原文,此处略
接口类型和结构体类型似乎是两个不同的世界。只有接口类型之间的赋值和转换会共享数据,其它情况都会复制数据。其它情况包括结构体之间的赋值,结构体转接口,接口转结构体。
不同接口变量之间的转换本质上只是调整了接口变量内部的类型指针,数据指针并不会发生改变。
15. 反射
反射的目标
- 获取变量的类型信息:例如这个类型的名称、占用字节数、所有的方法列表、所有的内部字段结构、底层存储类型等
- 动态修改变量的内部字段值:例如 JSON 的反序列化
reflect.kind
Go 语言的reflect包定义了十几种内置的「元类型」,每一种元类型都有一个整数编号,这个编号使用reflect.Kind类型表示。不同的结构体是不同的类型,但是它们都是同一个元类型Struct。包含不同子元素的切片也是不同的类型,但是它们都是同一个元类型Slice。
$GOROOT/src/reflect/type.go中部分源码如下:
// A Kind represents the specific kind of type that a Type represents.
// The zero Kind is not a valid kind.
type Kind uint
const (
Invalid Kind = iota // 不存在的无效类型
Bool
Int
Int8
Int16
Int32
Int64
Uint
Uint8
Uint16
Uint32
Uint64
Uintptr // 指针的整数类型,对指针进行整数运算时使用
Float32
Float64
Complex64
Complex128
Array // 数组类型
Chan // 通道类型
Func // 函数类型
Interface // 接口类型
Map // 字典类型
Ptr // 指针类型
Slice // 切片类型
String // 字符串类型
Struct // 结构体类型
UnsafePointer // unsafe.Pointer 类型
)
反射的基础代码
reflect包提供了两个基础反射方法,分别是TypeOf()和ValueOf()方法,分别用于获取变量的类型和值:
func TypeOf(v interface{}) Type
func ValueOf(v interface{}) Value
对结构体变量进行反射:
package main
import (
"fmt"
"reflect"
)
type Rect struct {
Width int
Height int
}
func main() {
var s int = 42
fmt.Println(reflect.TypeOf(s))
fmt.Println(reflect.ValueOf(s))
var r = Rect{200, 100}
fmt.Println(reflect.TypeOf(r))
fmt.Println(reflect.ValueOf(r))
}
------
int
42
main.Rect
{200 100}
Process finished with exit code 0
这两个方法的参数是interface{}类型,所以调用时编译器首先会将目标变量转换成interface{}类型。接口类型包含两个指针,一个指向类型,一个指向值。上面两个方法的作用就是将接口变量进行解剖从而分离出类型和值。
TypeOf()方法返回变量的类型信息得到的是一个类型为reflect.Type的变量ValueOf()方法返回变量的值信息得到的是一个类型为reflect.Value的变量
reflect.Type
它是一个接口类型,里面定义了非常多的方法用于获取和这个类型相关的一切信息:
type Type interface {
...
Method(i int) Method // 获取挂在类型上的第 i'th 个方法
...
NumMethod() int // 该类型上总共挂了几个方法
Name() string // 类型的名称
PkgPath() string // 所在包的名称
Size() uintptr // 占用字节数
String() string // 该类型的字符串形式
Kind() Kind // 元类型
...
Bits() // 占用多少位
ChanDir() // 通道的方向
...
Elem() Type // 数组,切片,通道,指针,字典(key)的内部子元素类型
Field(i int) StructField // 获取结构体的第 i'th 个字段
...
In(i int) Type // 获取函数第 i'th 个参数类型
Key() Type // 字典的 key 类型
Len() int // 数组的长度
NumIn() int // 函数的参数个数
NumOut() int // 函数的返回值个数
Out(i int) Type // 获取函数 第 i'th 个返回值类型
common() *rtype // 获取类型结构体的共同部分
uncommon() *uncommonType // 获取类型结构体的不同部分
}
所有的类型结构体都包含一个共同的部分信息,这部分信息使用rtype结构体描述,rtype实现了Type接口的所有方法:
// 基础类型 rtype 实现了 Type 接口
type rtype struct {
size uintptr // 占用字节数
ptrdata uintptr
hash uint32 // 类型的hash值
...
kind uint8 // 元类型
...
}
// 切片类型
type sliceType struct {
rtype
elem *rtype // 元素类型
}
// 结构体类型
type structType struct {
rtype
pkgPath name // 所在包名
fields []structField // 字段列表
}
...
reflect.Value
不同于reflect.Type的复杂,reflect.Value是一个非常简单的结构体:
type Value struct {
typ *rtype // 变量的类型结构体
ptr unsafe.Pointer // 数据指针
flag uintptr // 标志位
}
来看一个简单的例子:
package main
import (
"fmt"
"reflect"
)
func main() {
type SomeInt int
var s SomeInt = 42
var t = reflect.TypeOf(s)
var v = reflect.ValueOf(s)
// reflect.ValueOf(s).Type() 等价于 reflect.TypeOf(s)
fmt.Println(t == v.Type())
fmt.Println(v.Kind() == reflect.Int) // 元类型
// 将 Value 还原成原来的变量
var is = v.Interface()
fmt.Println(is.(SomeInt))
}
------
true
true
42
Process finished with exit code 0
Value结构体虽然简单,但是其附带的方法非常多,主要是用来方便用户读写ptr字段指向的数据内存。使用Value结构体提供的方法要比unsafe包更加简单直接:
func (v Value) SetLen(n int) // 修改切片的 len 属性
func (v Value) SetCap(n int) // 修改切片的 cap 属性
func (v Value) SetMapIndex(key, val Value) // 修改字典 kv
func (v Value) Send(x Value) // 向通道发送一个值
func (v Value) Recv() (x Value, ok bool) // 从通道接受一个值
// Send 和 Recv 的非阻塞版本
func (v Value) TryRecv() (x Value, ok bool)
func (v Value) TrySend(x Value) bool
// 获取切片、字符串、数组的具体位置的值进行读写
func (v Value) Index(i int) Value
// 根据名称获取结构体的内部字段值进行读写
func (v Value) FieldByName(name string) Value
// 将接口变量装成数组,一个是类型指针,一个是数据指针
func (v Value) InterfaceData() [2]uintptr
// 根据名称获取结构体的方法进行调用
// Value 结构体的数据指针 ptr 可以指向方法体
func (v Value) MethodByName(name string) Value
...
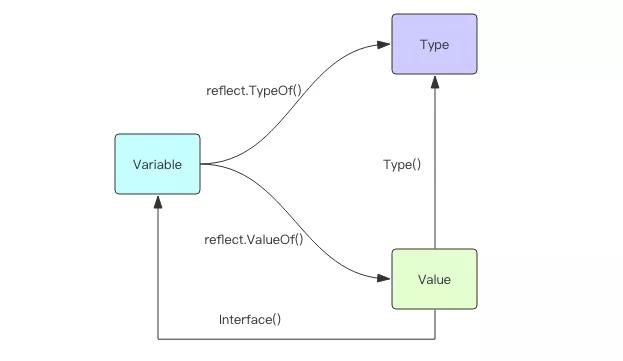
Go 语言官方的反射三大定律
- Reflection goes from interface value to reflection object.
- Reflection goes from reflection object to interface value.
- To modify a reflection object, the value must be settable.
第一条定律的意思是反射将接口变量转换成反射对象Type和Value:
func TypeOf(v interface{}) Type
func ValueOf(v interface{}) Value
第二条定律的意思是可以通过反射对象Value还原成原先的接口变量,指的就是Value结构体提供的Interface方法:
func (v Value) Interface() interface{}
注意:
v.Interface得到的是一个接口变量,还需要经过一次造型才能还原成原先的变量
第三条定律的意思是值类型的变量不可以通过反射来修改,因为在反射之前,传参的时候需要将值变量转换成接口变量,值内容会被浅拷贝,所以reflect包直接禁止了通过反射来修改值类型的变量:
package main
import "reflect"
func main() {
var s int = 42
var v = reflect.ValueOf(s)
v.SetInt(43)
}
------
panic: reflect: reflect.Value.SetInt using unaddressable value
goroutine 1 [running]:
reflect.flag.mustBeAssignable(0x82)
C:/Go/src/reflect/value.go:234 +0x15e
reflect.Value.SetInt(0x47b4a0, 0xc00004c000, 0x82, 0x2b)
C:/Go/src/reflect/value.go:1472 +0x36
main.main()
C:/Users/abel1/go/src/hello/routine.go:8 +0xc7
Process finished with exit code 2
可以看到当尝试通过反射来修改整型变量时,程序直接抛出了异常。而通过反射来修改指针变量指向的值还是可行的:
panic: reflect: reflect.Value.SetInt using unaddressable value
goroutine 1 [running]:
reflect.flag.mustBeAssignable(0x82)
C:/Go/src/reflect/value.go:234 +0x15e
reflect.Value.SetInt(0x47b4a0, 0xc00004c000, 0x82, 0x2b)
C:/Go/src/reflect/value.go:1472 +0x36
main.main()
C:/Users/abel1/go/src/hello/routine.go:8 +0xc7
Process finished with exit code 2
------
43
Process finished with exit code 0
结构体也是值类型,也必须通过指针类型来修改。下面尝试使用反射来动态修改结构体内部字段的值:
package main
import "fmt"
import "reflect"
type Rect struct {
Width int
Height int
}
func SetRectAttr(r *Rect, name string, value int) {
var v = reflect.ValueOf(r)
var field = v.Elem().FieldByName(name)
field.SetInt(int64(value))
}
func main() {
var r = Rect{50, 100}
SetRectAttr(&r, "Width", 100)
SetRectAttr(&r, "Height", 200)
fmt.Println(r)
}
-----
{100 200}
Process finished with exit code 0
16. 包管理 GOPATH 和 Vendor
系统包路径
Go 语言有很多内置包,内置包的使用需要用户手工import进来。Go 语言的内置包都是已经编译好的「包对象」,使用时编译器不需要进行二次编译:
// go sdk 安装路径
> go env GOROOT
/usr/local/go
> go env GOOS
darwin
> go env GOARCH
amd64
> ls /usr/local/go/darwin_amd64
total 22264
drwxr-xr-x 4 root wheel 136 11 3 05:11 archive
-rw-r--r-- 1 root wheel 169564 11 3 05:06 bufio.a
-rw-r--r-- 1 root wheel 177058 11 3 05:06 bytes.a
drwxr-xr-x 7 root wheel 238 11 3 05:11 compress
drwxr-xr-x 5 root wheel 170 11 3 05:11 container
-rw-r--r-- 1 root wheel 93000 11 3 05:06 context.a
drwxr-xr-x 21 root wheel 714 11 3 05:11 crypto
-rw-r--r-- 1 root wheel 24002 11 3 05:02 crypto.a
...
全局管理 GOPATH
Go 语言的GOPATH路径下存放了全局的第三方依赖包,当我们在代码里面import某个第三方包时,编译器都会到GOPATH路径下面来寻找。
> go env GOPATH
/Users/qianwp/go
GOPATH下有三个重要的子目录,分别是:
src:存放第三方包的源代码pkg:存放编译好的第三方包对象bin:存放第三方包提供的二进制可执行文件
当我们导入第三方包时,编译器优先寻找已经编译好的包对象,如果没有包对象,就会去源码目录寻找相应的源码来编译。使用包对象的编译速度会明显快于使用源码
友好的包路径
可以使用go get指令直接去相应的网站上拉取包代码,默认使用 HTTPS 协议下载代码仓库,可以使用-insecure参数切换到 HTTP 协议。
import "github.com/go-redis/redis"
import "golang.org/x/net"
import "gopkg.in/mgo.v2"
import "myhost.com/user/repo" // 个人提供的仓库
编写第一个模块
现在尝试编写第一个 Go 语言算法模块mathy,提供两个方法:Fib用来计算斐波那契数,Fact用来计算阶乘:
> mkdir -p $GOPATH/src/github.com/abelsu7/mathy
> cd $GOPATH/src/github.com/abelsu7/mathy
然后创建mathy.go文件:
package mathy
// 函数名大写,其它的包才可以看的见
func Fib(n int) int64 {
if n <= 1 {
return 1
}
var s = make([]int64, n+1)
s[0] = 1
s[1] = 1
for i := 2; i <= n; i++ {
s[i] = s[i-1] + s[i-2]
}
return s[n]
}
func Fact(n int) int64 {
if n <= 1 {
return 1
}
var s int64 = 1
for i := 2; i <= n; i++ {
s *= int64(i)
}
return s
}
之后去其他的任意空目录下编写main.go文件来使用mathy,但是不能在当前目录,因为同一个目录只能有同一个包名:
package main
import (
"fmt"
"github.com/abelsu7/mathy"
)
func main() {
fmt.Println(mathy.Fib(10))
fmt.Println(mathy.Fact(10))
}
------
89
3628800
Process finished with exit code 0
将代码推送到 Github 上,之后在任意 GO 语言环境下使用go get github.com/abelsu7/mathy即可将代码拉取到$GOPATH/src/目录下。
替换导入包名
import pmathy "github.com/pyloque/mathy"
import omathy "github.com/other/mathy"
无名导入
Go 语言还支持一种罕见的导入语法可以将其它包的所有类型变量都导入到当前的文件中,在使用相关类型变量时可以省去包名前缀:
package main
import "fmt"
import . "github.com/pyloque/mathy"
func main() {
fmt.Println(Fib(10))
fmt.Println(Fact(10))
}
go get/build/install
Go 提供了三个比较的常用的指令go get、go build、go install用来进行全局的包管理。
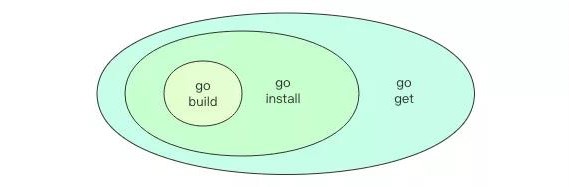
go build:仅编译。如果当前包里有main包,就会生成二进制文件。如果没有main包,则仅仅用来检查编译是否可以通过,编译完成后会丢弃所有临时包对象。如果指定-i参数,则会将编译成功的第三方依赖包对象安装到$GOPATH/pkg目录go install:先编译,再安装。将编译成的包对象安装到$GOPATH的pkg目录中,将编译成的可执行文件安装到$GOPATH的bin目录中。如果指定-i参数,还会安装编译成功的第三方依赖包对象go get:下载代码、编译和安装。安装内容包括包对象和可执行文件,但是不包括依赖包
使用
go run指令时如果发现程序启动了很久,就可以考虑先执行go build -i指令,将编译成功的依赖包都安装到$GOPATH/pkg,这样再次运行go run指令就会快很多
局部管理 Vendor
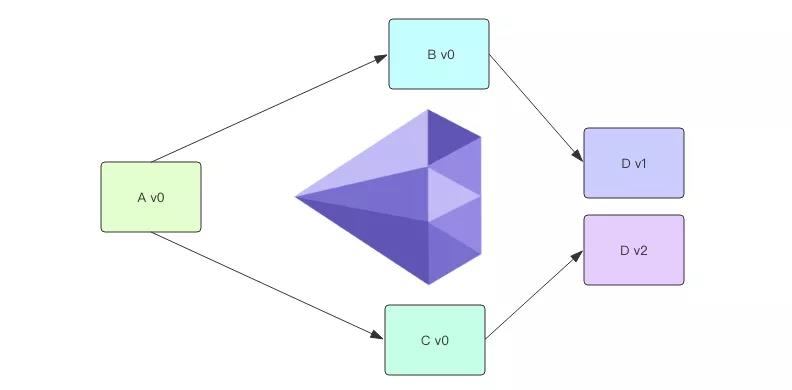
多版本依赖有一个专业的名称叫「钻石型」依赖。
为了解决这个问题,Go 1.6 引入了 Vendor 机制,就是在当前项目的目录下增加vendor子目录,将自己项目依赖的所有第三方包放到vendor目录里。这样当你导入第三方包的时候,优先去vendor目录里找你需要的第三方包。如果没有,再去$GOPATH全局路径下找。

使用 Vendor 有一个限制,那就是你不能将 Vendor 里面依赖的类型暴露到外面去,Vendor 里面的依赖包提供的功能仅限于当前项目使用,这就是 Vendor 的「隔离沙箱」。正是因为这个沙箱才使得项目里可以存在因为依赖传递导致的同一个依赖包的多个版本

