整理自书籍、博客、网络,更新中…

目录
0. 腾讯云肖光荣关于 KVM 的简述
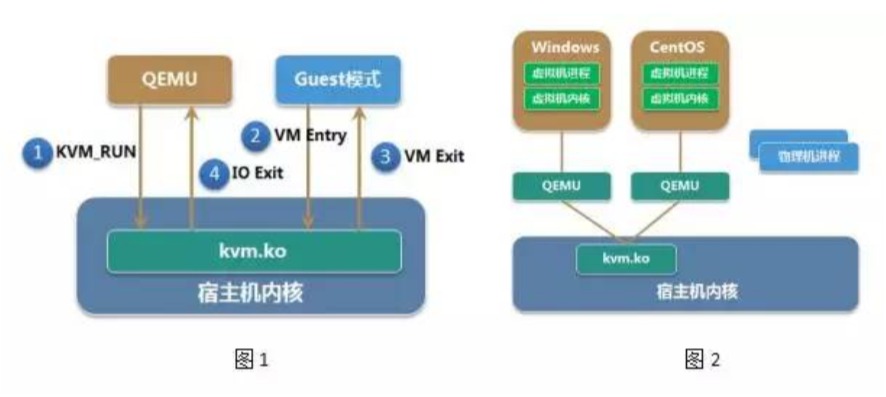
肖光荣:KVM 是 Kernel-based Virtual Machine 的简称,KVM 要求 CPU 支持硬件虚拟化技术(例如Intel VT或AMD-V),是 Linux 下的全虚拟化解决方案。KVM 由处于内核态的 KVM 模块kvm.ko和用户态的 QEMU 两部分构成。内核模块kvm.ko实现了 CPU 和内存虚拟化等决定关键性能和核心安全的功能,并向用户空间提供了使用这些功能的接口,QEMU 利用 KVM 模块提供的接口来实现设备模拟、I/O 虚拟化和网络虚拟化等。单个虚拟机是宿主机上的一个普通 QEMU 进程,虚拟机中的 CPU 核(vCPU)是 QEMU 的一个线程,VM 的物理地址空间是 QEMU 的虚拟地址空间(图 1)。
1. 虚拟化基础
虚拟化是云计算的基础。简单来说,虚拟化使得一台物理的服务器上可以跑多台虚拟机,虚拟机共享物理机的 CPU、内存、I/O 硬件资源,但逻辑上虚拟机之间是相互隔离的。
Host:宿主机,即物理机Guest:客户机,即虚拟机
Host将自己的硬件资源虚拟化,并提供给Guest使用,主要是通过Hypervisor来实现的。根据Hypervisor的实现方式和所处的位置,虚拟化又可以分为两种:1 型虚拟化和 2 型虚拟化。
1 型虚拟化
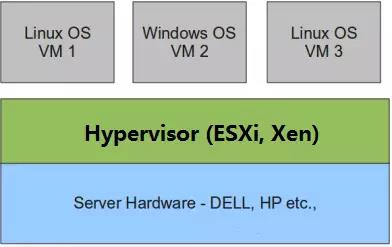
Hypervisor直接安装在物理机上,多个虚拟机在Hypervisor上运行。Hypervisor的实现方式一般是一个特殊定制的 Linux 系统,Xen 和 VMWare ESXi 都属于这个类型。
2 型虚拟化
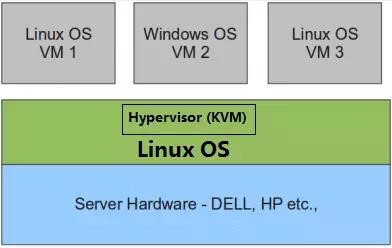
物理机上首先安装常规的操作系统,而Hypervisor作为 OS 上的一个程序模块运行,并对虚拟机进行管理。KVM、VirtualBox、VMWare Workstation 都属于这个类型。
由于 KVM 目前已经是 Linux 内核中的一个模块,因此也有人将其视为 1 型虚拟化
二者对比
理论上讲:
- 1 型虚拟化一般对硬件虚拟化功能进行了特别优化,性能上比 2 型虚拟化要高
- 2 型虚拟化因为基于普通的操作系统,会比较灵活,例如支持嵌套虚拟化
QEMU-KVM
- KVM 包含了一个内核加载模块
kvm.ko,它只会负责提供vCPU以及对虚拟内存进行管理和调度 - QEMU-KVM 是通过修改 QEMU 代码而得出的专门用来创建和管理虚拟机的管理工具,为的是 KVM 能更好的和内核打交道
- VM 运行期间,QEMU 会通过
kvm.ko模块提供的系统调用进入内核,由 KVM 负责将虚拟机置于特殊模式运行
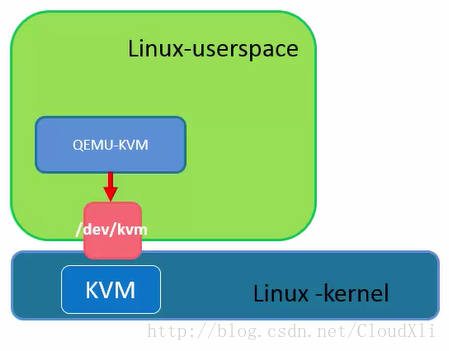
- QEMU-KVM 是 KVM 团队针对 QEMU 改善和二次开发的一套工具
/dev/kvm是 KVM 内核模块提供给用户空间的一个接口,这个接口被qemu-kvm调用,通过ioctl系统调用就可以给用户提供一个工具,用以创建、删除、管理虚拟机qemu-kvm就是通过open()、close()、ioctl()等方法去打开、关闭和调用这个接口,从而实现与 KVM 的互动
open("/dev/kvm")
ioctl(KVM_CREATE_VM)
ioctl(KVM_CREATE_VCPU)
for (;;) {
ioctl(KVM_RUN)
switch (exit_reason) {
case KVM_EXIT_IO: /* ... */
case KVM_EXIT_HLT: /* ... */
}
}
qemu-kvm通过/dev/kvm接口来调用 KVM:
- 打开
/dev/kvm设备 - 通过
KVM_CREATE_VM创建一个虚拟机对象 - 通过
KVM_CREATE_VCPU为虚拟机创建vcpu对象 - 通过
KVM_RUN设置vcpu为运行状态
外设是怎么管理的
虚拟机只有vCPU和vMEM是无法运行的,还需要外设的支持。真实的外设需要利用 Linux 系统内核进行管理,而通常来说我们使用的还是虚拟外设。VM 要和虚拟外设进行交互的话,就需要利用 QEMU 模拟的虚拟外设。
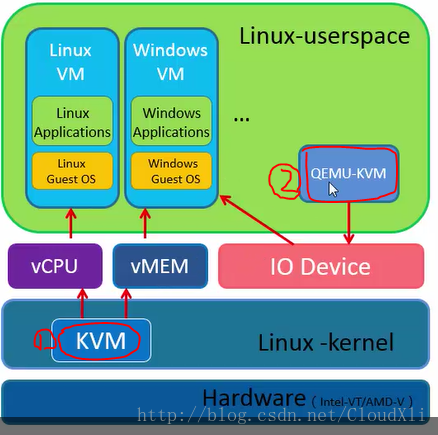
2. KVM 原理简介
KVM 实现主要基于Intel-V或者AMD-V提供的虚拟化平台,利用普通的 Linux 进程运行虚拟态的指令集,模拟虚拟机监视器和 CPU。KVM 本身并不提供硬件虚拟化操作,其 I/O 操作都借助 QEMU 完成。
KVM 全称为Kernel-based Virtual Machine,也就是说 KVM 是基于 Linux 内核实现的。KVM 有一个核心的内核模块kvm.ko,它只用于管理 vCPU 和内存。
作为一个
Hypervisor,KVM 本身只关注虚拟机调度和内存管理这两个方面,I/O 外设的任务就交给了 Linux 内核和 QEMU
libvirt
libvirt 主要包含三个模块:后台daemon程序libvirtd、API 库以及命令行工具virsh。
libvirtd:守护进程,接收并处理 API 请求- API 库使得其他人可以开发出基于 libvirt 的虚拟机管理工具,例如
virt-manager virsh是经常会使用到的 KVM 命令行工具
Guest 特点
Guest作为一个普通进程运行于宿主机Guest的 CPU(vCPU)作为进程的线程存在,并受到宿主机内核的调度Guest继承了宿主机内核的一些属性,例如Huge PagesGuest的磁盘 I/O 和网络 I/O 会受到宿主机设置的影响Guest通过宿主机上的虚拟网桥与外部相连
3. KVM 整体架构
概览
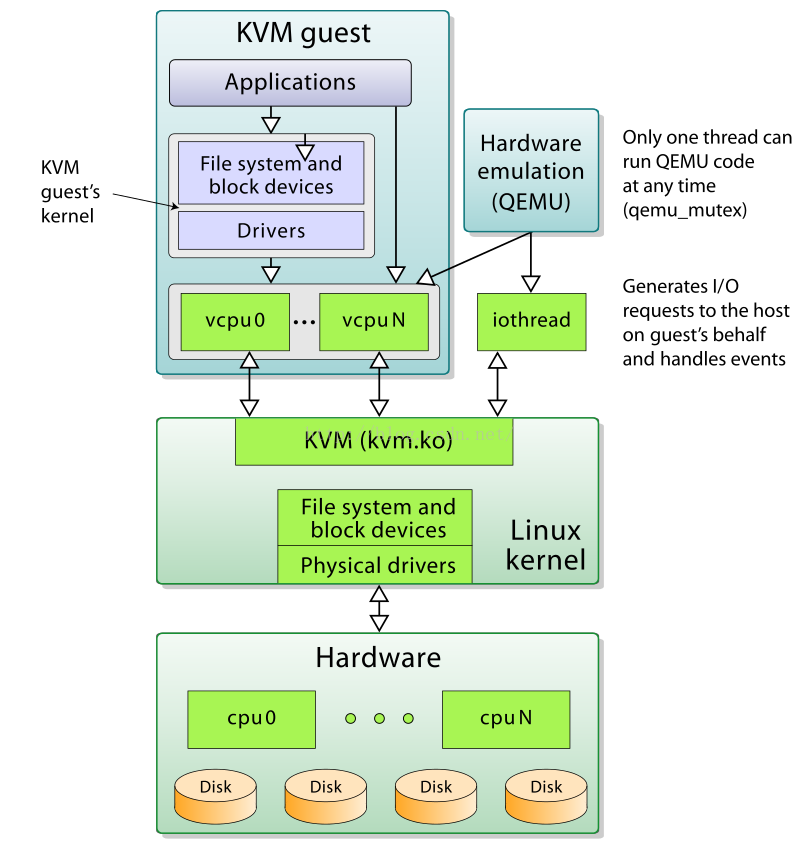
每一个虚拟机Guest在Host上都被模拟为一个 QEMU 进程,即emulation进程。创建虚拟机后,使用virsh命令即可查看:
> virsh list --all
Id Name State
----------------------------------------------------
1 kvm-01 running
> ps aux | grep qemu
libvirt+ 20308 15.1 7.5 5023928 595884 ? Sl 17:29 0:10 /usr/bin/qemu-system-x86_64 -name kvm-01 -S -machine pc-i440fx-wily,accel=kvm,usb=off -m 2048 -realtime mlock=off -smp 2 qemu ....
可以看到,此虚拟机就是一个普通的 Linux 进程,有自己的PID,并且有四个线程。线程数量不是固定的,但是至少会有三个(vCPU、I/O、Signal)。其中有两个是vCPU线程,一个I/O线程,还有一个Signal信号处理线程。
> pstree -p 20308
qemu-system-x86(20308)-+-{qemu-system-x86}(20353)
|-{qemu-system-x86}(20408)
|-{qemu-system-x86}(20409)
|-{qemu-system-x86}(20412)
虚拟 CPU
Guest的所有用户级别的指令集,都会直接由宿主机线程执行,此线程会调用 KVM 的ioctl方式提供的接口加载Guest的指令,并在特殊的 CPU 模式下运行。这样就不需要经过 CPU 指令集的软件模拟转换,降低了虚拟化的成本,这也是 KVM 优于其他虚拟化方式的原因之一。
KVM 对外提供了一个虚拟设备/dev/kvm,可以通过ioctl(I/O 设备带外管理接口)来对 KVM 进行操作。
虚拟 I/O 设备
Guest虽然作为一个进程存在,但其内核的所有驱动都依然存在。只是硬件设备由 QEMU 模拟。Guest的所有硬件操作都会由 QEMU 来接管,QEMU 负责与真实的宿主机硬件打交道。
虚拟内存
Guest的内存在Host上由 Emulator 提供(即 QEMU)。对于 QEMU 来说,Guest访问的内存就是 QEMU 的虚拟地址空间。Guest上需要经过一次虚拟地址到物理地址的转换,转换得到的Guest的物理地址其实也就是 QEMU 的虚拟地址。这时 QEMU 再做一次转换,将虚拟地址转换为Host的物理地址。
虚拟机启动过程
第一步,获取到kvm句柄
kvmfd = open("/dev/kvm", O_RDWR);
第二步,创建虚拟机,获取到虚拟机句柄。
vmfd = ioctl(kvmfd, KVM_CREATE_VM, 0);
第三步,为虚拟机映射内存,还有其他的PCI,信号处理的初始化。
ioctl(kvmfd, KVM_SET_USER_MEMORY_REGION, &mem);
第四步,将虚拟机镜像映射到内存,相当于物理机的boot过程,把镜像映射到内存。
第五步,创建vCPU,并为vCPU分配内存空间。
ioctl(kvmfd, KVM_CREATE_VCPU, vcpuid);
vcpu->kvm_run_mmap_size = ioctl(kvm->dev_fd, KVM_GET_VCPU_MMAP_SIZE, 0);
第五步,创建vCPU个数的线程并运行虚拟机。
ioctl(kvm->vcpus->vcpu_fd, KVM_RUN, 0);
第六步,线程进入循环,并捕获虚拟机退出原因,做相应的处理。
这里的退出并不一定是虚拟机关机,虚拟机如果遇到IO操作,访问硬件设备,缺页中断等都会退出执行,退出执行可以理解为将CPU执行上下文返回到QEMU。
虚拟机的启动过程总结如下:
- 创建
KVM句柄 - 创建
VM - 分配内存
- 加载镜像到内存
- 启动线程执行
KVM_RUN
open("/dev/kvm")
ioctl(KVM_CREATE_VM)
ioctl(KVM_CREATE_VCPU)
for (;;) {
ioctl(KVM_RUN)
switch (exit_reason) {
case KVM_EXIT_IO: /* ... */
case KVM_EXIT_HLT: /* ... */
}
}
4. KVM 内存虚拟化及其实现
客户机物理地址空间
为了实现内存虚拟化,让Guest使用一个隔离的、从零开始且连续的内存空间,KVM 引入了一层新的地址空间,即客户机物理地址空间(Guest Physical Address,GPA)。
这个地址空间并不是真正的物理地址空间,它只是Host虚拟地址空间在Guest地址空间的一个映射。对客户机来说,客户机物理地址空间都是从零开始的连续地址空间。但对宿主机来说,客户机的物理地址空间并不一定是连续的,客户机物理地址空间有可能映射在若干个不连续的宿主机地址区间,如下图所示:
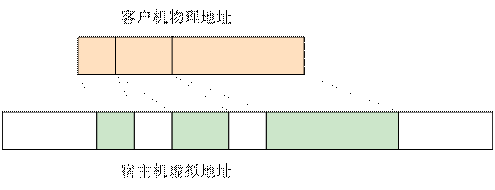
为了将客户机物理地址转换成宿主机虚拟地址(Host Virtual Address,HVA),KVM 用一个kvm_memory_slot数据结构来记录每一个地址区间的映射关系,此数据结构包含了对应此映射区间的起始客户机页帧号(Guest Frame Number,GFN)、映射的内存页数目以及起始宿主机虚拟地址,从而实现 GPA 到 HPA 的转换。
实现内存虚拟化,最主要的是实现客户机虚拟地址GVA到宿主机物理地址HPA之间的转换。如果通过之前提到的两步映射的方式,客户机的每次内存访问都需要 KVM 介入,并由软件进行多次地址转换,其效率是非常低的。
因此,为了提高GVA到HPA的转换效率,KVM 提供了两种实现方式来进行GVA到HPA之间的直接转换:
- 影子页表(Shadow Page Table):纯软件的实现方式
- 基于硬件对虚拟化的支持
影子页表
由于宿主机 MMU 不能直接装载客户机的页表来进行内存访问,所以当客户机访问宿主机物理内存时,需要经过多次地址转换。而通过影子页表,则可以实现客户机虚拟地址到宿主机物理地址的直接转换:
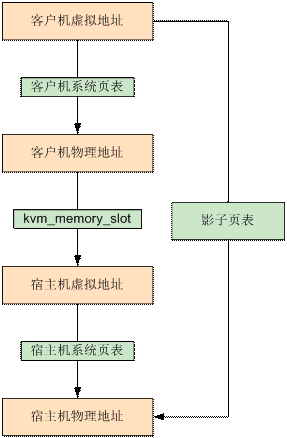
影子页表简化了地址转换过程,实现了客户机虚拟地址空间到宿主机物理地址空间的直接映射。
由于客户机中每个进程都有自己的虚拟地址空间,所以 KVM 需要为客户机中的每个进程页表都维护一套相应的影子页表。在客户机访问内存时,真正被装入宿主机 MMU 的是客户机当前页表所对应的影子页表
在使用影子页表的情况下,客户机的大多数内存访问都可以在没有 KVM 介入的情况下正常执行,没有额外的地址转换开销,也就大大提高了客户机运行的效率。
但是影子页表的引入也意味着 KVM 需要为每个客户机的每个进程页表都要维护一套相应的影子页表,这会带来较大的内存开销。此外,客户机页表和影子页表之间的同步也较为复杂。因此,Intel 的 EPT(Extent Page Table)技术和 AMD 的 NPT(Nest Page Table)技术都为内存虚拟化提供了硬件支持,在硬件层面上实现了GVA到HPA之间的转换。
EPT 页表
EPT(Extent Page Table) 技术在原有客户机页表对GVA到GPA映射的基础上,又引入了 EPT 页表来实现GPA到HPA的另一次映射,这两次地址映射都是由硬件自动完成。
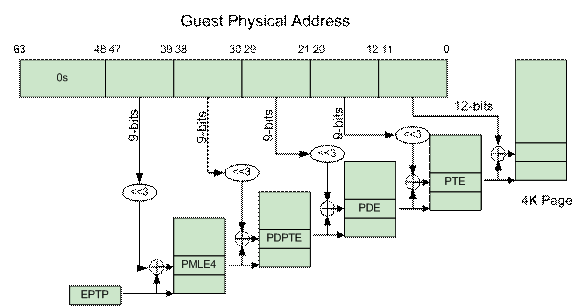
EPT 页表相对于影子页表,其实现方式大大简化。而且,由于客户机内部的缺页异常不会导致客户机退出,因此也提高了客户机性能。此外,KVM 只需为每个客户机维护一套 EPT 页表,从而大大减少了内存的额外开销。
5. virtio 半虚拟化
全虚拟化和半虚拟化
- 全虚拟化:
Guest运行于物理机的Hypervisor之上,Guest操作系统并不知道它已被虚拟化,而且不需要任何更改就可以在该配置下工作 - 半虚拟化:
Guest操作系统不仅知道它运行在Hypervisor之上,还包含了让Guest操作系统更高效的过渡到Hypervisor的代码
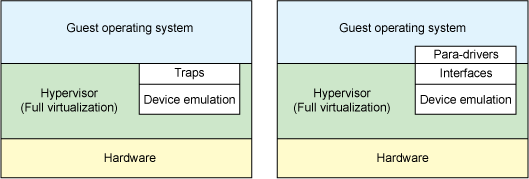
在传统的全虚拟化环境中,Hypervisor必须捕捉Guest的 I/O 请求,然后模拟物理硬件的行为,虽然比较灵活,但是效率较低。
而在半虚拟化环境中,Guest知道自己运行在Hypervisor之上,并且包含了充当前端程序的驱动程序。Hypervisor为特定的设备模拟实现后端驱动程序。通过前端和后端驱动程序中的virtio,为模拟设备提供标准化接口,从而提高了代码的跨平台重用率与运行效率。
针对 Linux 的抽象
总结来看,virtio是对半虚拟化Hypervisor中的一组通用模拟设备的抽象。有了半虚拟化Hypervisor之后,Guest操作系统就能够实现一组通用的接口,针对不同的后端驱动程序采用特定的设备模拟。后端驱动程序不需要是通用的,因为它们只需要实现前端所需的行为。
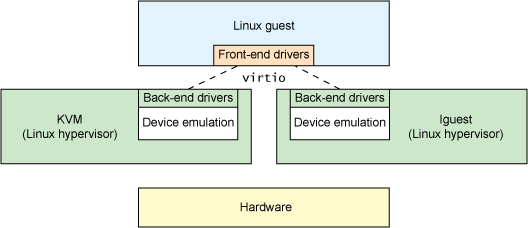
virtio 架构
virtio API依赖一个简单的缓冲抽象来封装Guest操作系统所需要的命令和数据。在前端和后端驱动程序之外,virtio还定义了两个层来支持Guest到Hypervisor的通信。
6. 镜像文件格式
- Qemu虚拟机QCOW2格式镜像文件的组成部分及关键算法分析 | 开源中国
- KVM-QEMU, QCOW2, QEMU-IMG and Snapshots | 开源中国
- KVM 磁盘扩容 | 51CTO
- RAW(裸) 与 QCOW2(写时复制) 的区别 | CSDN
- QCOW2实现原理的一般性思考 | CSDN
- QEMU 使用的镜像文件:qcow2 与 raw | CSDN
- qcow2 文件格式详解(I)| 简书
参考文章
- 【必看】KVM 虚拟化原理探究 - Overview | CSDN
- CloudMan
- KVM 内存虚拟化及其实现 | IBM Developer
- 【必看】虚拟化技术之KVM,搭建KVM | CSDN
- Virtio:针对 Linux 的 I/O 虚拟化框架 | IBM Developer
- Linux 虚拟化技术和 PCI 透传技术 | IBM Developer
- CPU 和内存虚拟化原理 - CloudMan | CSDN
- 热迁移、RTC 计时与安全增强 - 腾讯云 KVM 性能优化实践经验谈 | InfoQ
- qemu+kvm的IO路径分析 | CSDN
- QEMU-KVM 原理综述 | FlyFlyPeng
- 阿里云郑晓:浅谈GPU虚拟化技术(一)| 阿里云栖社区
- 阿里云郑晓:浅谈GPU虚拟化技术(二)| 阿里云栖社区
- 阿里云郑晓:浅谈GPU虚拟化技术(三)| 阿里云栖社区
- 浅谈GPU虚拟化技术(四)- GPU分片虚拟化 | 阿里云栖社区
- 浅谈GPU虚拟化技术(五)- VDI 的用户体验
- 一文带你领略虚拟化领域顶级技术会议 KVM Forum 2018 | 阿里云栖社区
- 【必看】KVM 虚拟化原理探究—启动过程及各部分虚拟化原理 | CSDN
- KVM 计算虚拟化原理,偏基础 | 博客园
- Qemu虚拟机QCOW2格式镜像文件的组成部分及关键算法分析 | 开源中国
- KVM-QEMU, QCOW2, QEMU-IMG and Snapshots | 开源中国
- KVM 磁盘扩容 | 51CTO
- RAW(裸) 与 QCOW2(写时复制) 的区别 | CSDN
- QCOW2实现原理的一般性思考 | CSDN
- QEMU 使用的镜像文件:qcow2 与 raw | CSDN
- KVM虚拟化原理 | 开源中国
- virtio基本原理(kvm半虚拟化驱动) | 开源中国
- qemu,kvm,qemu-kvm,xen,libvir 区别 | 开源中国

