1. 内存虚拟化概述
1.1 Overview
QEMU-KVM 的内存虚拟化是由 QEMU 和 KVM 二者共同实现的,其本质上是一个将 Guest 虚拟内存转换成 Host 物理内存的过程。概括来看,主要有以下几点:
- Guest 启动时,由 QEMU 从它的进程地址空间申请内存并分配给 Guest 使用,即内存的申请是在用户空间完成的
- 通过 KVM 提供的 API,QEMU 将 Guest 内存的地址信息传递并注册到 KVM 中维护,即内存的管理是由内核空间的 KVM 实现的
- 整个转换过程涉及 GVA、GPA、HVA、HPA 四种地址,Guest 的物理地址空间从 QEMU 的虚拟地址空间中分配
- 内存虚拟化的关键在于维护 GPA 到 HVA 的映射关系,Guest 使用的依然是 Host 的物理内存
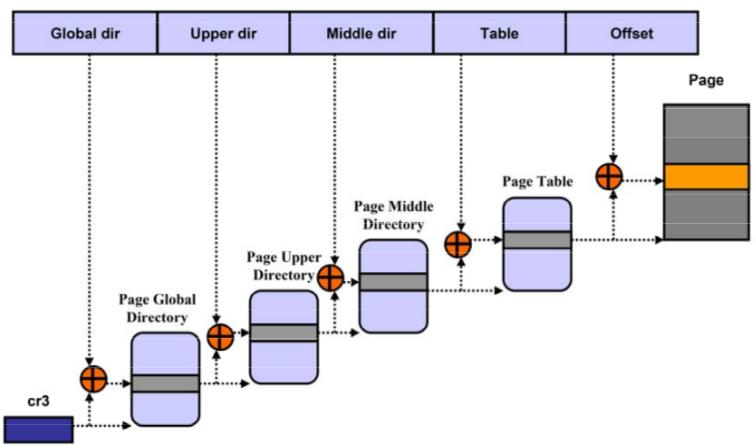
1.2 传统的地址转换
64 位 CPU 上支持 48 位的虚拟地址寻址空间,和 52 位的物理地址寻址空间。Linux 采用 4 级页表机制将虚拟地址(VA)转换成物理地址(PA),先从页表的基地址寄存器CR3中读取页表的起始地址,然后加上页号得到对应的页表项,从中取出页的物理地址,加上偏移量就得到 PA。
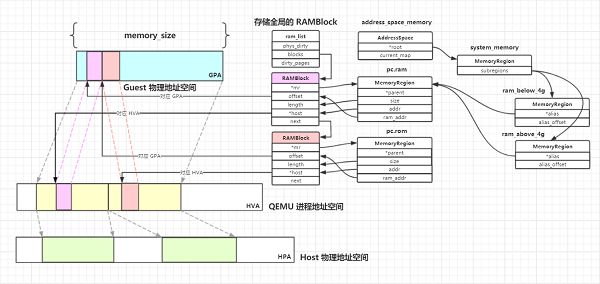
1.3 QEMU 的内存结构
QEMU 利用mmap系统调用,在进程的虚拟地址空间中申请连续大小的空间,作为 Guest 的物理内存。
QEMU 作为 Host 上的一个进程运行,Guest 的每个 vCPU 都是 QEMU 进程的一个子线程。而 Guest 实际使用的仍是 Host 上的物理内存,因此对于 Guest 而言,在进行内存寻址时需要完成以下地址转换过程:
Guest虚拟内存地址(GVA)
|
Guest线性地址
|
Guest物理地址(GPA)
| Guest
------------------
| Host
Host虚拟地址(HVA)
|
Host线性地址
|
Host物理地址(HPA)
其中,虚拟地址到线性地址的转换过程可以省略,因此 KVM 的内存寻址主要涉及以下四种地址的转换:
Guest虚拟内存地址(GVA)
|
Guest物理地址(GPA)
| Guest
------------------
| Host
Host虚拟地址(HVA)
|
Host物理地址(HPA)
其中,GVA->GPA的映射由 Guest OS 维护,HVA->HPA的映射由 Host OS 维护,因此需要一种机制,来维护GPA->HVA之间的映射关系。
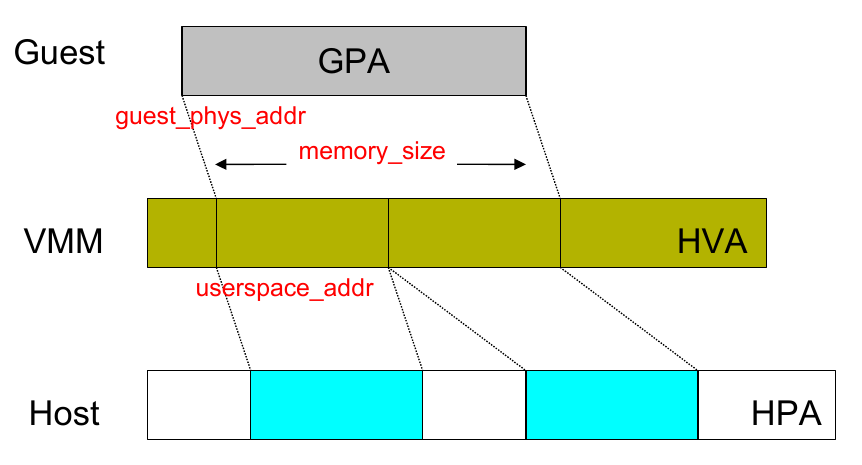
常用的实现有SPT(Shadow Page Table)和EPT/NPT,前者通过软件维护影子页表,后者通过硬件特性实现二级映射。
1.3.1 影子页表
KVM 通过维护记录GVA->HPA的影子页表 SPT,减少了地址转换带来的开销,可以直接将 GVA 转换为 HPA。
在软件虚拟化的内存转换中,GVA 到 GPA 的转换通过查询 CR3 寄存器来完成,CR3 中保存了 Guest 的页表基地址,然后载入 MMU 中进行地址转换。
在加入了 SPT 技术后,当 Guest 访问 CR3 时,KVM 会捕获到这个操作EXIT_REASON_CR_ACCESS,之后 KVM 会载入特殊的 CR3 和影子页表,欺骗 Guest 这就是真实的 CR3。之后就和传统的访问内存方式一致,当需要访问物理内存的时候,只会经过一层影子页表的转换。
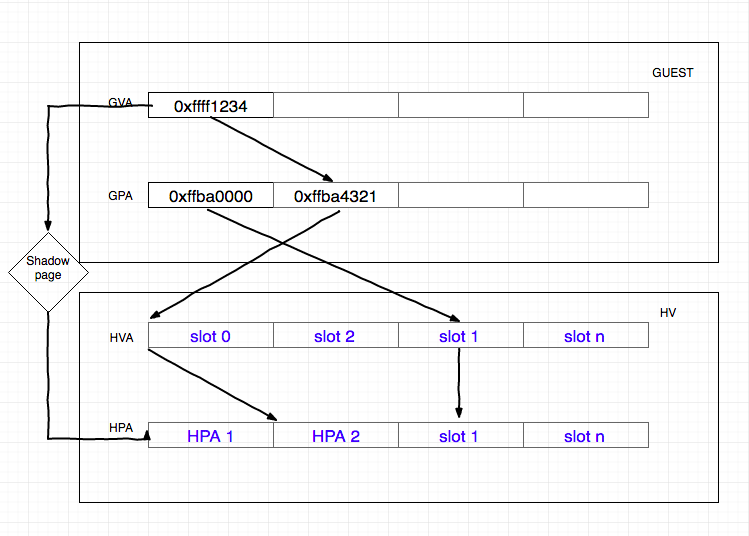
影子页表由 KVM 维护,实际上就是一个 Guest 页表到 Host 页表的映射。KVM 会将 Guest 的页表设置为只读,当 Guest OS 对页表进行修改时就会触发 Page Fault,VM-EXIT 到 KVM,之后 KVM 会对 GVA 对应的页表项进行访问权限检查,结合错误码进行判断:
- 如果是 Guest OS 引起的,则将该异常注入回去,Guest OS 将调用自己的缺页处理函数,申请一个 Page,并将 Page 的 GPA 填充到上级页表项中
- 如果是 Guest OS 的页表和 SPT 不一致引起的,则同步 SPT,根据 Guest 页表和 mmap 映射找到 GPA 到 HVA 的映射关系,然后在 SPT 中增加/更新
GVA-HPA表项
当 Guest 切换进程时,会把带切换进程的页表基址载入到 Guest 的 CR3 中,导致 VM-EXIT 到 KVM 中。KVM 再通过哈希表找到对应的 SPT,然后加载到机器的 CR3 中。
影子页表的引入,减少了GVA->HPA的转换开销,但是缺点在于需要为 Guest 的每个进程都维护一个影子页表,这将带来很大的内存开销。同时影子页表的建立是很耗时的,如果 Guest 的进程过多,将导致影子页表频繁切换。因此 Intel 和 AMD 在此基础上提供了基于硬件的虚拟化技术。
1.3.2 EPT 硬件加速
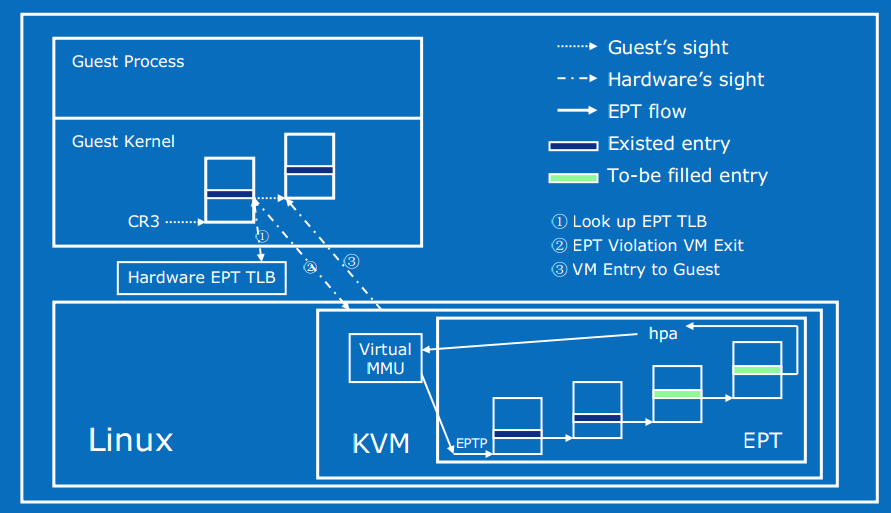
Intel EPT 技术引入了 EPT(Extended Page Table)和 EPTP(EPT base pointer)的概念。EPT 中维护着 GPA 到 HPA 的映射,而 EPTP 负责指向 EPT。
在 Guest OS 运行时,Guest 对应的 EPT 地址被加载到 EPTP,而 Guest OS 当前运行的进程页表基址被加载到 CR3。于是在进行地址转换时,首先通过 CR3 指向的页表实现 GVA 到 GPA 的转换,再通过 EPTP 指向的 EPT 完成 GPA 到 HPA 的转换。当发生 EPT Page Fault 时,需要 VM-EXIT 到 KVM,更新 EPT。
- 优点:Guest 的缺页在 Guest OS 内部处理,不会 VM-EXIT 到 KVM 中。地址转化基本由硬件(MMU)查页表来完成,大大提升了效率,且只需为 Guest 维护一份 EPT 页表,减少内存的开销
- 缺点:两级页表查询,只能寄望于 TLB 命中
1.4 QEMU 的主要工作
内存虚拟化的目的就是让虚拟机能够无缝的访问内存。有了 Intel EPT 的支持后,CPU 在 VMX non-root 状态时进行内存访问会再做一次 EPT 转换。在这个过程中,QEMU 会负责以下内容:
- 首先需要从自己的进程地址空间中申请内存用于 Guest
- 需要将上一步中申请到的内存的虚拟地址(HVA)和 Guest 的物理地址之间的映射关系传递给 KVM,即
GPA->HVA - 需要组织一系列的数据结构来管理虚拟内存空间,并在内存拓扑结构更改时将最新的内存信息同步至 KVM 中
1.5 QEMU 和 KVM 的工作分界
QEMU 和 KVM 之间是通过 KVM 提供的ioctl()接口进行交互的。在内核的kvm_vm_ioctl()中,设置虚拟机内存的系统调用为KVM_SET_USER_MEMORY_REGION:
static long kvm_vm_ioctl(struct file *filp,
unsigned int ioctl, unsigned long arg)
{
/* ... */
case KVM_SET_USER_MEMORY_REGION: { // 在 KVM 中注册用户空间传入的内存信息
struct kvm_userspace_memory_region kvm_userspace_mem;
r = -EFAULT;
// 将传入的数据结构复制到内核空间
if (copy_from_user(&kvm_userspace_mem, argp, sizeof kvm_userspace_mem))
goto out;
// 实际进行处理的函数
r = kvm_vm_ioctl_set_memory_region(kvm, &kvm_userspace_mem, 1);
if (r)
goto out;
break;
}
/* ... */
}
可以看到这里需要传递的参数类型为kvm_userspace_memory_region:
/* for KVM_SET_USER_MEMORY_REGION */
struct kvm_userspace_memory_region {
__u32 slot; // slot 编号
__u32 flags; // 标志位,例如是否追踪脏页、是否可用等
__u64 guest_phys_addr; // Guest 物理地址,即 GPA
__u64 memory_size; // 内存大小,单位 bytes
__u64 userspace_addr; // 从 QEMU 进程地址空间中分配内存的起始地址,即 HVA
};
KVM_SET_USER_MEMORY_REGION这个 ioctl 主要目的就是设置GPA->HVA的映射关系,KVM 会继续调用kvm_vm_ioctl_set_memory_region(),在内核空间维护并管理 Guest 的内存。
2. 相关数据结构
2.1 AddressSpace
2.1.1 结构体定义
QEMU 用 AddressSpace 结构体表示 Guest 中 CPU/设备看到的内存,类似于物理机中地址空间的概念,但在这里表示的是 Guest 的一段地址空间,如内存地址空间address_space_memory、I/O 地址空间address_space_io,它在 QEMU 源码memory.c中定义:
/* A system address space - I/O, memory, etc. */
struct AddressSpace {
MemoryRegion *root; // 根级 MemoryRegion
FlatView current_map; // 对应的平面展开视图 FlatView
int ioeventfd_nb;
MemoryRegionIoeventfd *ioeventfds;
};
每个 AddressSpace 一般包含一系列的 MemoryRegion:root指针指向根级 MemoryRegion,而root可能有自己的若干个 subregions,于是形成树状结构。这些 MemoryRegion 通过树连接起来,树的根即为 AddressSpace 的root域。
2.1.2 全局变量
另外,QEMU 中有两个全局的静态 AddressSpace,在memory.c中定义:
static AddressSpace address_space_memory; // 内存地址空间
static AddressSpace address_space_io; // I/O 地址空间
其root域分别指向之后会提到的两个 MemoryRegion 类型变量:system_memory、system_io。
2.2 MemoryRegion
2.2.1 结构体定义
MemoryRegion 表示在 Guest Memory Layout 中的一段内存区域,它是联系 GPA 和 RAMBlocks(描述真实内存)之间的桥梁,在memory.h中定义:
struct MemoryRegion {
/* All fields are private - violators will be prosecuted */
const MemoryRegionOps *ops; // 回调函数集合
void *opaque;
MemoryRegion *parent; // 父 MemoryRegion 指针
Int128 size; // 该区域内存的大小
target_phys_addr_t addr; // 在 Address Space 中的地址,即 HVA
void (*destructor)(MemoryRegion *mr);
ram_addr_t ram_addr; // MemoryRegion 的起始地址,即 GPA
bool subpage;
bool terminates;
bool readable;
bool ram; // 是否表示 RAM
bool readonly; /* For RAM regions */
bool enabled; // 是否已经通知 KVM 使用这段内存
bool rom_device;
bool warning_printed; /* For reservations */
MemoryRegion *alias; // 是否为 MemoryRegion alias
target_phys_addr_t alias_offset; // 若为 alias,在原 MemoryRegion 中的 offset
unsigned priority;
bool may_overlap;
QTAILQ_HEAD(subregions, MemoryRegion) subregions; // 子区域链表头
QTAILQ_ENTRY(MemoryRegion) subregions_link; // 子区域链表节点
QTAILQ_HEAD(coalesced_ranges, CoalescedMemoryRange) coalesced;
const char *name; // MemoryRegion 的名字,调试时使用
uint8_t dirty_log_mask; // 表示哪一种 dirty map 被使用,共分三种
unsigned ioeventfd_nb;
MemoryRegionIoeventfd *ioeventfds;
};
2.2.2 全局变量
在 QEMU 的exec.c中也定义了两个静态的 MemoryRegion 指针变量:
static MemoryRegion *system_memory; // 内存 MemoryRegion,对应 address_space_memory
static MemoryRegion *system_io; // I/O MemoryRegion,对应 address_space_io
与两个全局 AddressSpace 对应,即 AddressSpace 的root域指向这两个 MemoryRegion。
2.2.3 MemoryRegion 的类型
MemoryRegion 有多种类型,可以表示一段 RAM、ROM、MMIO、alias。
若为 alias 则表示一个 MemoryRegion 的部分区域,例如 QEMU 会为pc.ram这个表示 RAM 的 MemoryRegion 添加两个 alias:ram-below-4g和ram-above-4g,之后会看到具体的代码实例。
另外,MemoryRegion 也可以表示一个 container,这就表示它只是其他若干个 MemoryRegion 的容器
那么要如何创建不同类型的 MemoryRegion 呢?在 QEMU 中实际上是通过调用不同的初始化函数区分的。根据不同的初始化函数及其功能,可以将 MemoryRegion 划分为以下三种类型:
- 根级 MemoryRegion:直接通过
memory_region_init初始化,没有自己的内存,用于管理 subregion,例如system_memory:
void memory_region_init(MemoryRegion *mr,
const char *name,
uint64_t size)
{
mr->ops = NULL;
mr->parent = NULL;
mr->size = int128_make64(size);
if (size == UINT64_MAX) {
mr->size = int128_2_64();
}
mr->addr = 0;
mr->subpage = false;
mr->enabled = true;
mr->terminates = false; // 非实体 MemoryRegion,搜索时会继续前往其 subregions
mr->ram = false; // 根级 MemoryRegion 不分配内存
mr->readable = true;
mr->readonly = false;
mr->rom_device = false;
mr->destructor = memory_region_destructor_none;
mr->priority = 0;
mr->may_overlap = false;
mr->alias = NULL;
QTAILQ_INIT(&mr->subregions);
memset(&mr->subregions_link, 0, sizeof mr->subregions_link);
QTAILQ_INIT(&mr->coalesced);
mr->name = g_strdup(name);
mr->dirty_log_mask = 0;
mr->ioeventfd_nb = 0;
mr->ioeventfds = NULL;
}
可以看到mr->addr被设置为 0,而mr->ram_addr则并没有初始化。
- 实体 MemoryRegion:通过
memory_region_init_ram()初始化,有自己的内存(从 QEMU 进程地址空间中分配),大小为size,例如ram_memory、pci_memory:
void *pc_memory_init(MemoryRegion *system_memory,
const char *kernel_filename,
const char *kernel_cmdline,
const char *initrd_filename,
ram_addr_t below_4g_mem_size,
ram_addr_t above_4g_mem_size,
MemoryRegion *rom_memory,
MemoryRegion **ram_memory)
{
MemoryRegion *ram, *option_rom_mr;
/* ...*/
/* Allocate RAM. We allocate it as a single memory region and use
* aliases to address portions of it, mostly for backwards compatibility
* with older qemus that used qemu_ram_alloc().
*/
ram = g_malloc(sizeof(*ram));
// 调用 memory_region_init_ram 对 ram_memory 进行初始化
memory_region_init_ram(ram, "pc.ram", below_4g_mem_size + above_4g_mem_size);
vmstate_register_ram_global(ram);
*ram_memory = ram;
/* ... */
}
void memory_region_init_ram(MemoryRegion *mr,
const char *name,
uint64_t size)
{
memory_region_init(mr, name, size);
mr->ram = true;
mr->terminates = true;
mr->destructor = memory_region_destructor_ram;
mr->ram_addr = qemu_ram_alloc(size, mr);
}
可以看到这里是先调用了memory_region_init(),之后设置 RAM 属性,并继续调用qemu_ram_alloc()分配内存。
- 别名 MemoryRegion:通过
memory_region_init_alias()初始化,没有自己的内存,表示实体 MemoryRegion 的一部分。通过 alias 成员指向实体 MemoryRegion,alias_offset为在实体 MemoryRegion 中的偏移量,例如ram_below_4g、ram_above_4g:
void *pc_memory_init(MemoryRegion *system_memory,
const char *kernel_filename,
const char *kernel_cmdline,
const char *initrd_filename,
ram_addr_t below_4g_mem_size,
ram_addr_t above_4g_mem_size,
MemoryRegion *rom_memory,
MemoryRegion **ram_memory)
{
MemoryRegion *ram_below_4g, *ram_above_4g;
/* ... */
ram_below_4g = g_malloc(sizeof(*ram_below_4g));
// 调用 memory_region_init_alias 对 ram_below_4g 进行初始化
memory_region_init_alias(ram_below_4g, "ram-below-4g", ram, 0, below_4g_mem_size);
/* ... */
}
void memory_region_init_alias(MemoryRegion *mr,
const char *name,
MemoryRegion *orig,
target_phys_addr_t offset,
uint64_t size)
{
memory_region_init(mr, name, size);
mr->alias = orig; // 指向实体 MemoryRegion
mr->alias_offset = offset;
}
2.3 RAMBlock
2.3.1 结构体定义
MemoryRegion 用来描述一段逻辑层面上的内存区域,而记录实际分配的内存地址信息的结构体则是 RAMBlock,在cpu-all.h中定义:
typedef struct RAMBlock {
struct MemoryRegion *mr; // 唯一对应的 MemoryRegion
uint8_t *host; // RAMBlock 关联的内存,即 HVA
ram_addr_t offset; // RAMBlock 在 VM 物理内存中的偏移量,即 GPA
ram_addr_t length; // RAMBlock 的长度
uint32_t flags;
char idstr[256]; // RAMBlock 的 id
QLIST_ENTRY(RAMBlock) next; // 指向下一个 RAMBlock
#if defined(__linux__) && !defined(TARGET_S390X)
int fd;
#endif
} RAMBlock;
可以看到在 RAMBlock 中host和offset域分别对应了 HVA 和 GPA,因此也可以说 RAMBlock 中存储了GPA->HVA的映射关系,另外每一个 RAMBlock 都会指向其所属的 MemoryRegion。
2.3.2 全局变量 ram_list
QEMU 在cpu-all.h中定义了一个全局变量ram_list,以链表的形式维护了所有的 RAMBlock:
typedef struct RAMList {
uint8_t *phys_dirty;
QLIST_HEAD(, RAMBlock) blocks;
uint64_t dirty_pages;
} RAMList;
extern RAMList ram_list;
每一个新分配的 RAMBlock 都会被插入到ram_list的头部。如需查找地址所对应的 RAMBlock,则需要遍历ram_list,当目标地址落在当前 RAMBlock 的地址区间时,该 RAMBlock 即为查找目标。
2.3.3 AS、MR、RAMBlock 之间的关系
AddressSpace、MemoryRegion、RAMBlock 之间的关系如下所示:
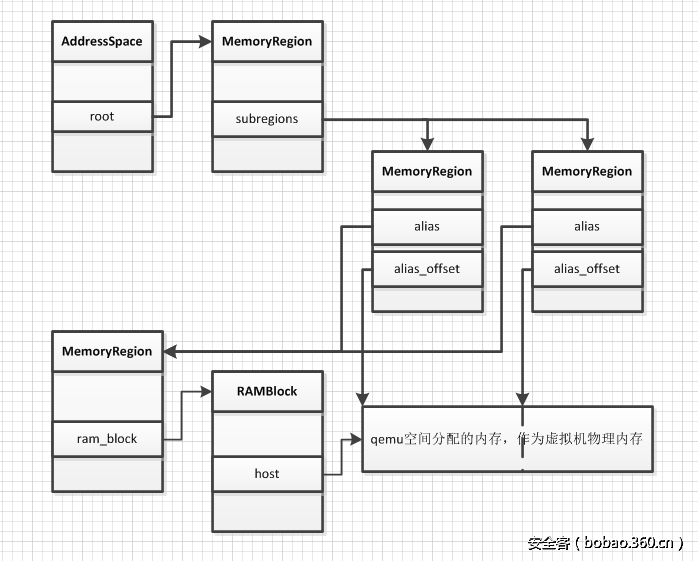
可以看到 AddressSpace 的root域指向根级 MemoryRegion,AddressSpace 是由root域指向的 MemoryRegion 及其子树共同表示的。MemoryRegion 作为一个逻辑层面的内存区域,还需借助分布在其中的 RAMBlock 来存储真实的地址映射关系。
下图是我根据自己的理解绘制的三者之间的关系图:
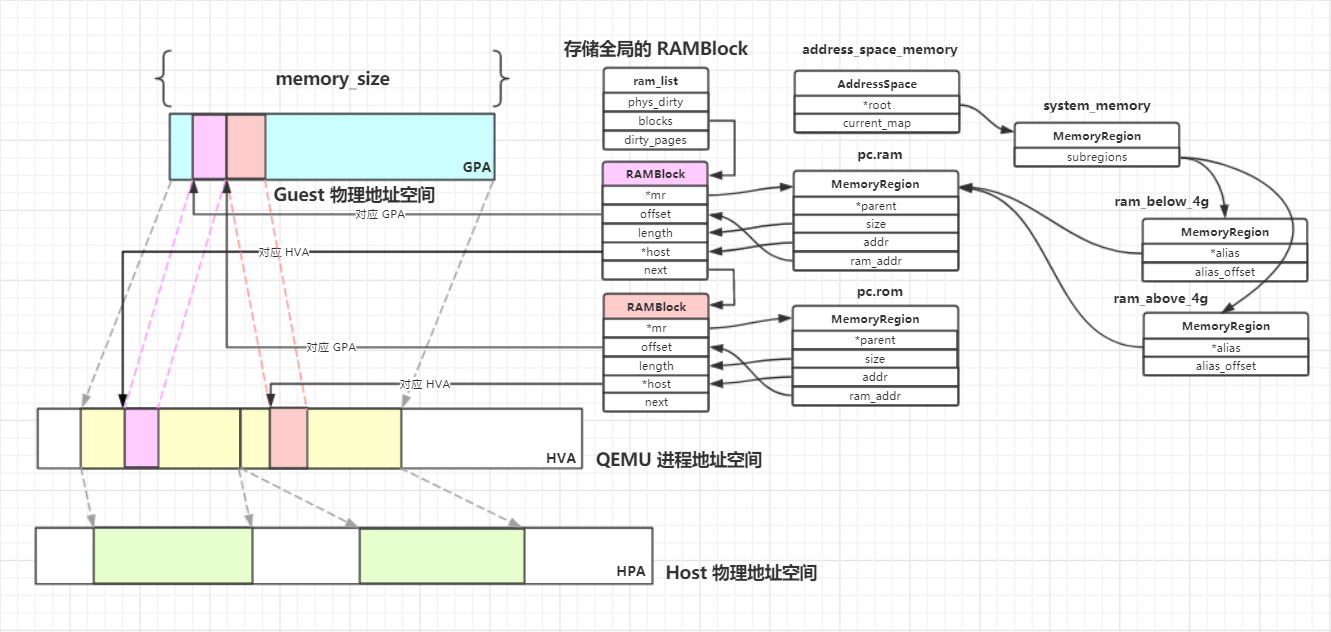
如图所示,以address_space_memory为例,其root域对应的 MemoryRegion 为system_memory。system_memory的 subregions 为两个 alias MemoryRegion:ram_below_4g、ram_above_4g,均指向pc.ram这个实体 MemoryRegion。pc.ram的内存实际上通过 RAMBlock 分配,其addr与ram_addr域分别对应了 RAMBlock 的 HVA、GPA。QEMU 从自己的进程地址空间中为该 RAMBlock 分配内存后,将其mr域指向pc.ram,至此就完成了 QEMU 侧的内存分配。
2.4 FlatView
AddressSpace 的root域及其子树共同构成了 Guest 的物理地址空间,但这些都是在 QEMU 侧定义的。要传入 KVM 进行设置时,复杂的树状结构是不利于内核进行处理的,因此需要将其转换为一个“平坦”的地址模型,也就是一个从零开始、只包含地址信息的数据结构,这在 QEMU 中通过 FlatView 来表示。每个 AddressSpace 都有一个与之对应的 FlatView 指针current_map,表示其对应的平面展开视图。
2.4.1 结构体定义
FlatView 在memory.c中定义:
/* Flattened global view of current active memory hierarchy. Kept in sorted
* order.
*/
struct FlatView {
FlatRange *ranges; // 对应的 FlatRange 数组
unsigned nr; // FlatRange 的数目
unsigned nr_allocated; // 当前数组的项数
};
其中,ranges是一个数组,记录了 FlatView 下所有的 FlatRange。
2.4.2 FlatRange
在 FlatView 中,FlatRange 表示在 FlatView 中的一段内存范围,同样在memory.c中定义:
/* Range of memory in the global map. Addresses are absolute. */
struct FlatRange {
MemoryRegion *mr; // 指向所属的 MemoryRegion
target_phys_addr_t offset_in_region; // 在全局 MemoryRegion 中的 offset,对应 GPA
AddrRange addr; // 代表的地址区间,对应 HVA
uint8_t dirty_log_mask;
bool readable;
bool readonly;
};
每个 FlatRange 对应一段虚拟机物理地址区间,各个 FlatRange 不会重叠,按照地址的顺序保存在数组中,具体的地址范围由一个 AddrRange 结构来描述:
/*
* AddrRange 用于表示 FlatRange 的起始地址及大小
*/
struct AddrRange {
Int128 start;
Int128 size;
};
2.5 MemoryRegionSection
2.5.1 结构体定义
在 QEMU 中,还有几个起到中介作用的结构体,MemoryRegionSection 就是其中之一。
之前介绍的 FlatRange 代表一个物理地址空间的片段,偏向于描述在 Host 侧即 AddressSpace 中的分布,而 MemoryRegionSection 则代表在 Guest 侧即 MemoryRegion 中的片段。MemoryRegionSection 在memory.h中定义:
/**
* MemoryRegionSection: describes a fragment of a #MemoryRegion
*
* @mr: the region, or %NULL if empty
* @address_space: the address space the region is mapped in
* @offset_within_region: the beginning of the section, relative to @mr's start
* @size: the size of the section; will not exceed @mr's boundaries
* @offset_within_address_space: the address of the first byte of the section
* relative to the region's address space
* @readonly: writes to this section are ignored
*/
struct MemoryRegionSection {
MemoryRegion *mr; // 所属的 MemoryRegion
MemoryRegion *address_space; // 关联的 AddressSpace
target_phys_addr_t offset_within_region; // 在 MemoryRegion 内部的 offset
uint64_t size; // Section 的大小
target_phys_addr_t offset_within_address_space; // 在 AddressSpace 内部的 offset
bool readonly; // 是否为只读
};
offset_within_region:在所属 MemoryRegion 中的 offset。一个 AddressSpace 可能由多个 MemoryRegion 组成,因此该 offset 是局部的offset_within_address_space:在所属 AddressSpace 中的 offset,它是全局的
2.5.2 和其他数据结构之间的关系
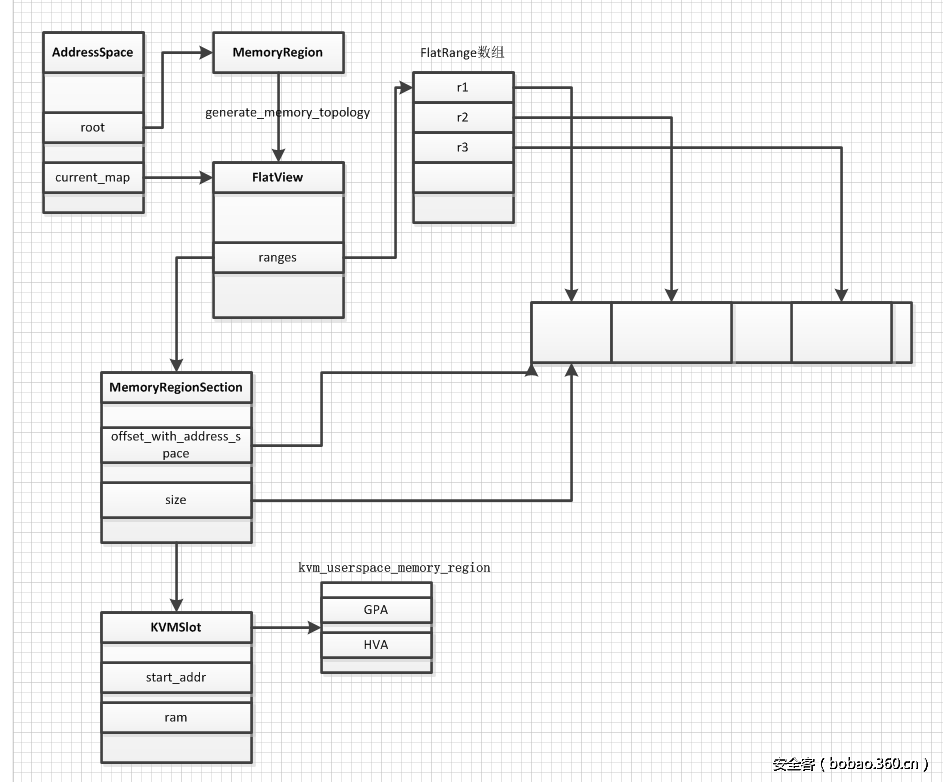
- AddressSpace 的
root指向对应的根级 MemoryRegion,current_map指向root通过generate_memory_topology()生成的 FlatView - FlatView 中的
ranges数组表示该 MemoryRegion 所表示的 Guest 地址区间,并按照地址的顺序进行排列 - MemoryRegionSection 由
ranges数组中的 FlatRange 对应生成,作为注册到 KVM 中的基本单位
2.6 KVM 相关
QEMU 在用户空间申请内存后,需要将内存信息通过一系列系统调用传入内核空间的 KVM,由 KVM 侧进行管理,因此 QEMU 侧也定义了一些用于向 KVM 传递参数的结构体。
2.6.1 KVMSlot
在kvm-all.c中定义,是 KVM 中内存管理的基本单位:
typedef struct KVMSlot
{
target_phys_addr_t start_addr; // Guest 物理地址,GPA
ram_addr_t memory_size; // 内存大小
void *ram; // QEMU 用户空间地址,HVA
int slot; // Slot 编号
int flags; // 标志位,例如是否追踪脏页、是否可用等
} KVMSlot;
KVMSlot 类似于内存插槽的概念,在 KVMState 的定义中可以看到,最多支持 32 个 KVMSlot:
struct KVMState
{
KVMSlot slots[32]; // 最多支持 32 个 KVMSlot
/* ... */
}
KVMState *kvm_state;
2.6.2 kvm_userspace_memory_region
调用ioctl(KVM_SET_USER_MEMORY_REGION)时需要向 KVM 传递的参数,在kvm.h中定义
/* for KVM_SET_USER_MEMORY_REGION */
struct kvm_userspace_memory_region {
__u32 slot; // slot 编号
__u32 flags; // 标志位,例如是否追踪脏页、是否可用等
__u64 guest_phys_addr; // Guest 物理地址,GPA
__u64 memory_size; // 内存大小,bytes
__u64 userspace_addr; // 从 QEMU 进程空间分配的起始地址,HVA
};
2.7 MemoryListener
2.7.1 结构体定义
为了监控虚拟机的物理地址访问,对于每一个 AddressSpace,都会有一个 MemoryListener 与之对应。每当物理映射GPA->HVA发生改变时,就会回调这些函数。MemoryListener 是对一些事件的回调函数合集,在memory.h中定义:
/**
* MemoryListener: callbacks structure for updates to the physical memory map
*
* Allows a component to adjust to changes in the guest-visible memory map.
* Use with memory_listener_register() and memory_listener_unregister().
*/
struct MemoryListener {
void (*begin)(MemoryListener *listener);
void (*commit)(MemoryListener *listener);
void (*region_add)(MemoryListener *listener, MemoryRegionSection *section);
void (*region_del)(MemoryListener *listener, MemoryRegionSection *section);
void (*region_nop)(MemoryListener *listener, MemoryRegionSection *section);
void (*log_start)(MemoryListener *listener, MemoryRegionSection *section);
void (*log_stop)(MemoryListener *listener, MemoryRegionSection *section);
void (*log_sync)(MemoryListener *listener, MemoryRegionSection *section);
void (*log_global_start)(MemoryListener *listener);
void (*log_global_stop)(MemoryListener *listener);
void (*eventfd_add)(MemoryListener *listener, MemoryRegionSection *section,
bool match_data, uint64_t data, EventNotifier *e);
void (*eventfd_del)(MemoryListener *listener, MemoryRegionSection *section,
bool match_data, uint64_t data, EventNotifier *e);
/* Lower = earlier (during add), later (during del) */
unsigned priority;
MemoryRegion *address_space_filter;
QTAILQ_ENTRY(MemoryListener) link;
};
2.7.2 全局变量 memory_listeners
所有的 MemoryListener 都会挂在全局变量memory_listeners链表上,在memory.c中定义:
static QTAILQ_HEAD(memory_listeners, MemoryListener) memory_listeners
= QTAILQ_HEAD_INITIALIZER(memory_listeners);
在memory.c中枚举了 ListenerDireciton:
enum ListenerDirection { Forward, Reverse };
另外,system_memory、system_io这两个全局 MemoryRegion 分别注册了core_memory_listener和io_memory_listener,在exec.c中定义:
// 对应 system_memory 这个 MemoryRegion
static MemoryListener core_memory_listener = {
.begin = core_begin,
.commit = core_commit,
.region_add = core_region_add,
.region_del = core_region_del,
.region_nop = core_region_nop,
.log_start = core_log_start,
.log_stop = core_log_stop,
.log_sync = core_log_sync,
.log_global_start = core_log_global_start,
.log_global_stop = core_log_global_stop,
.eventfd_add = core_eventfd_add,
.eventfd_del = core_eventfd_del,
.priority = 0,
};
// 对应 system_io 这个 MemoryRegion
static MemoryListener io_memory_listener = {
.begin = io_begin,
.commit = io_commit,
.region_add = io_region_add,
.region_del = io_region_del,
.region_nop = io_region_nop,
.log_start = io_log_start,
.log_stop = io_log_stop,
.log_sync = io_log_sync,
.log_global_start = io_log_global_start,
.log_global_stop = io_log_global_stop,
.eventfd_add = io_eventfd_add,
.eventfd_del = io_eventfd_del,
.priority = 0,
};
除此之外,QEMU 还在全局注册了kvm_memory_listener,在kvm-all.c中定义,用于将 QEMU 侧内存拓扑结构的改动同步更新至 KVM 中:
// 同时监听 system_memory、system_io
static MemoryListener kvm_memory_listener = {
.begin = kvm_begin,
.commit = kvm_commit,
.region_add = kvm_region_add,
.region_del = kvm_region_del,
.region_nop = kvm_region_nop,
.log_start = kvm_log_start,
.log_stop = kvm_log_stop,
.log_sync = kvm_log_sync,
.log_global_start = kvm_log_global_start,
.log_global_stop = kvm_log_global_stop,
.eventfd_add = kvm_eventfd_add,
.eventfd_del = kvm_eventfd_del,
.priority = 10,
};
2.8 重要数据结构总览
2.8.1 数据结构及其含义总览
| 结构体名 | 定义 | 说明 |
|---|---|---|
| AddressSpace | memory.c | VM 能看到的一段地址空间,偏向 Host 侧 |
| MemoryRegion | memory.h | 地址空间中一段逻辑层面的内存区域,偏向 Guest 侧 |
| RAMBlock | cpu-all.h | 记录实际分配的内存地址信息,存储了GPA->HVA的映射关系 |
| FlatView | memory.c | MemoryRegion 对应的平面展开视图,包含一个 FlatRange 类型的 ranges 数组 |
| FlatRange | memory.c | 对应一段虚拟机物理地址区间,各个 FlatRange 不会重叠,按照地址的顺序保存在数组中 |
| MemoryRegionSection | memory.h | 表示 MemoryRegion 中的片段 |
| MemoryListener | memory.h | 回调函数集合 |
| KVMSlot | kvm-all.c | KVM 中内存管理的基本单位,表示一个内存插槽 |
| kvm_userspace_memory_region | kvm.h | 调用ioctl(KVM_SET_USER_MEMORY_REGION)时需要向 KVM 传递的参数 |
2.8.2 全局变量总览
- 两个 static AddressSpace,在
memory.c中定义:
static AddressSpace address_space_memory; // 内存地址空间,对应 system_memory
static AddressSpace address_space_io; // I/O 地址空间,对应 system_io
- 两个 static MemoryRegion 指针,在
exec.c中定义:
static MemoryRegion *system_memory; // 用于管理内存 subregion 的根级 MemoryRegion
static MemoryRegion *system_io; // 用于管理 I/O subregion 的根级 MemoryRegion
- 一个 RAMList,在
exec.c中定义:
RAMList ram_list = { .blocks = QLIST_HEAD_INITIALIZER(ram_list.blocks) }; // 用于管理全局的 RAMBlock
- 一个 MemoryListener 全局链表,在
memory.c中定义
static QTAILQ_HEAD(memory_listeners, MemoryListener) memory_listeners
= QTAILQ_HEAD_INITIALIZER(memory_listeners);
- 三个 MemoryListener,在
exec.c和kvm-all.c中定义:
// 对应 system_memory 这个 MemoryRegion
static MemoryListener core_memory_listener = {
.begin = core_begin,
.commit = core_commit,
.region_add = core_region_add,
.region_del = core_region_del,
.region_nop = core_region_nop,
.log_start = core_log_start,
.log_stop = core_log_stop,
.log_sync = core_log_sync,
.log_global_start = core_log_global_start,
.log_global_stop = core_log_global_stop,
.eventfd_add = core_eventfd_add,
.eventfd_del = core_eventfd_del,
.priority = 0,
};
// 对应 system_io 这个 MemoryRegion
static MemoryListener io_memory_listener = {
.begin = io_begin,
.commit = io_commit,
.region_add = io_region_add,
.region_del = io_region_del,
.region_nop = io_region_nop,
.log_start = io_log_start,
.log_stop = io_log_stop,
.log_sync = io_log_sync,
.log_global_start = io_log_global_start,
.log_global_stop = io_log_global_stop,
.eventfd_add = io_eventfd_add,
.eventfd_del = io_eventfd_del,
.priority = 0,
};
// 在全局注册,同时监听 system_memory、system_io
static MemoryListener kvm_memory_listener = {
.begin = kvm_begin,
.commit = kvm_commit,
.region_add = kvm_region_add,
.region_del = kvm_region_del,
.region_nop = kvm_region_nop,
.log_start = kvm_log_start,
.log_stop = kvm_log_stop,
.log_sync = kvm_log_sync,
.log_global_start = kvm_log_global_start,
.log_global_stop = kvm_log_global_stop,
.eventfd_add = kvm_eventfd_add,
.eventfd_del = kvm_eventfd_del,
.priority = 10,
};
3. 具体实现机制
QEMU 的内存申请流程大致可分为三个部分:回调函数的注册、AddressSpace 的初始化、实际内存的分配。下面将根据在vl.c的main()函数中的调用顺序分别介绍。
3.1 回调函数的注册
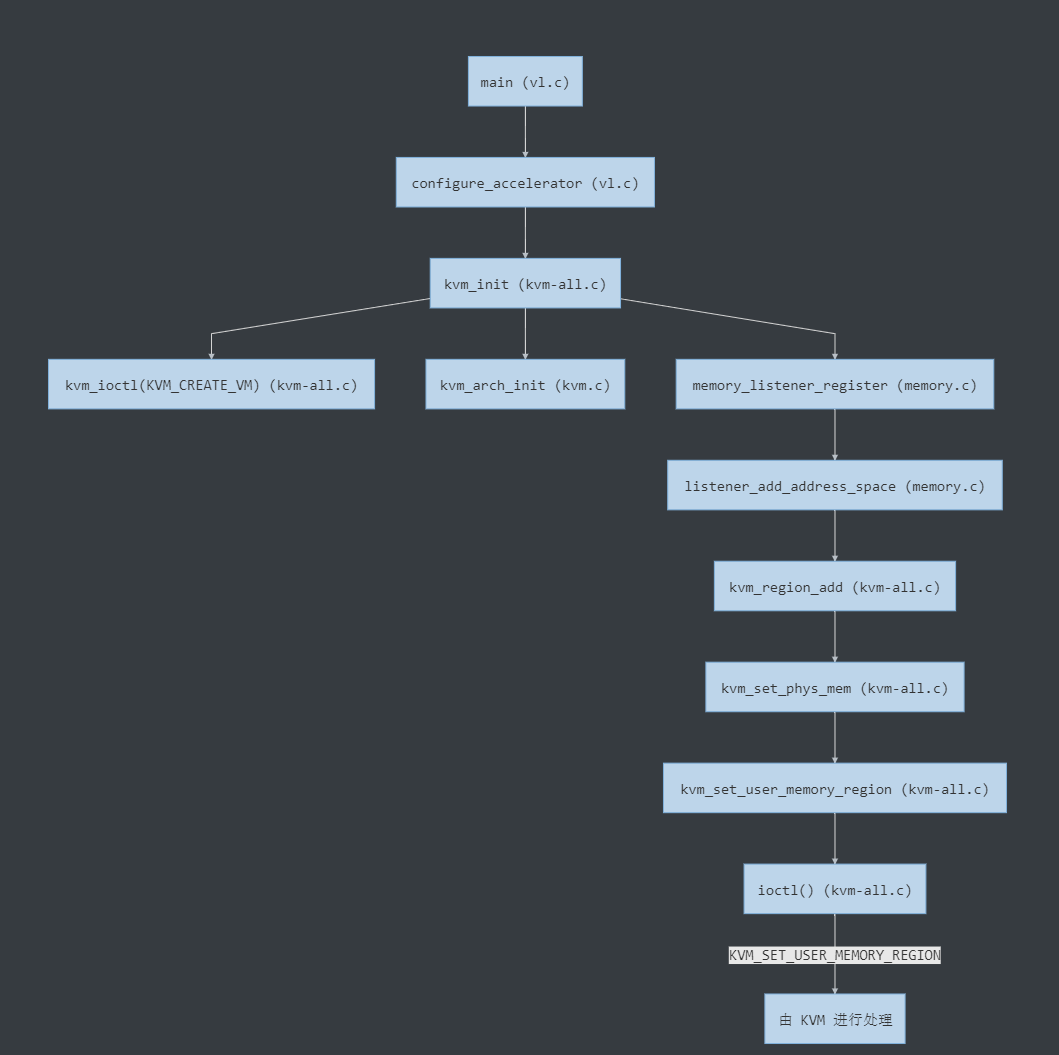
int main()
└─ static int configure_accelerator()
└─ int kvm_init() // 初始化 KVM
├─ int kvm_ioctl(KVM_CREATE_VM) // 创建 VM
├─ int kvm_arch_init() // 针对不同的架构进行初始化
└─ void memory_listener_register() // 注册 kvm_memory_listener
└─ static void listener_add_address_space() // 调用 region_add 回调
└─ static void kvm_region_add() // region_add 对应的回调实现
└─ static void kvm_set_phys_mem() // 根据传入的 section 填充 KVMSlot
└─ static int kvm_set_user_memory_region()
└─ int ioctl(KVM_SET_USER_MEMORY_REGION)
进入configure_accelerator()后,QEMU 会先调用configure_accelerator()设置 KVM 的加速支持,之后进入kvm_init()。该函数主要完成对 KVM 的初始化,包括一些常规检查如 CPU 个数、KVM 版本等,之后通过kvm_ioctl(KVM_CREATE_VM)与内核交互,创建 KVM 虚拟机。在kvm_init()的最后,会调用memory_listener_register()注册kvm_memory_listener:
int kvm_init(void)
{
/* ... */
s->vmfd = kvm_ioctl(s, KVM_CREATE_VM, 0); // 创建 VM
/* ... */
ret = kvm_arch_init(s); // 针对不同的架构进行初始化
if (ret < 0) {
goto err;
}
/* ... */
memory_listener_register(&kvm_memory_listener, NULL); // 注册回调函数
/* ... */
}
该注册函数本身并不复杂,结合备注来看:
void memory_listener_register(MemoryListener *listener, MemoryRegion *filter)
{
MemoryListener *other = NULL;
listener->address_space_filter = filter;
/* 若 memory_listeners 为空或当前 listener 的优先级大于最后一个 listener 的优先级,则直接在末尾插入 */
if (QTAILQ_EMPTY(&memory_listeners)
|| listener->priority >= QTAILQ_LAST(&memory_listeners,
memory_listeners)->priority) {
QTAILQ_INSERT_TAIL(&memory_listeners, listener, link);
} else {
/* 遍历链表,按照优先级升序排列 */
QTAILQ_FOREACH(other, &memory_listeners, link) {
if (listener->priority < other->priority) {
break;
}
}
/* 插入 listener */
QTAILQ_INSERT_BEFORE(other, listener, link);
}
/* 对于以下 AddressSpace,设置其对应的 listener */
listener_add_address_space(listener, &address_space_memory);
listener_add_address_space(listener, &address_space_io);
}
最后的listener_add_address_space()主要是将listener注册到其对应的 AddressSpace 上,并根据 AddressSpace 对应的 FlatRange 数组,生成 MemoryRegionSection,并注册到 KVM 中:
static void listener_add_address_space(MemoryListener *listener,
AddressSpace *as)
{
FlatRange *fr;
/* 若非注册的 AddressSpace,直接返回 */
if (listener->address_space_filter
&& listener->address_space_filter != as->root) {
return;
}
/* 开启内存脏页记录 */
if (global_dirty_log) {
listener->log_global_start(listener);
}
/* 遍历 AddressSpace 对应的 FlatRange 数组,并将其转换成 MemoryRegionSection */
FOR_EACH_FLAT_RANGE(fr, &as->current_map) {
MemoryRegionSection section = {
.mr = fr->mr,
.address_space = as->root,
.offset_within_region = fr->offset_in_region,
.size = int128_get64(fr->addr.size),
.offset_within_address_space = int128_get64(fr->addr.start),
.readonly = fr->readonly,
};
/* 将 section 所代表的内存区域注册到 KVM 中 */
listener->region_add(listener, §ion);
}
}
由于此时 AddressSapce 尚未初始化,所以此处的循环为空,仅是在全局注册了kvm_memory_listener。最后调用了kvm_memory_listener->region_add(),对应的实现是kvm_region_add(),该函数最终会通过ioctl(KVM_SET_USER_MEMORY_REGION),将 QEMU 侧申请的内存信息传入 KVM 进行注册,这里的流程会在下一部分进行分析。
3.2 AddressSpace 的初始化
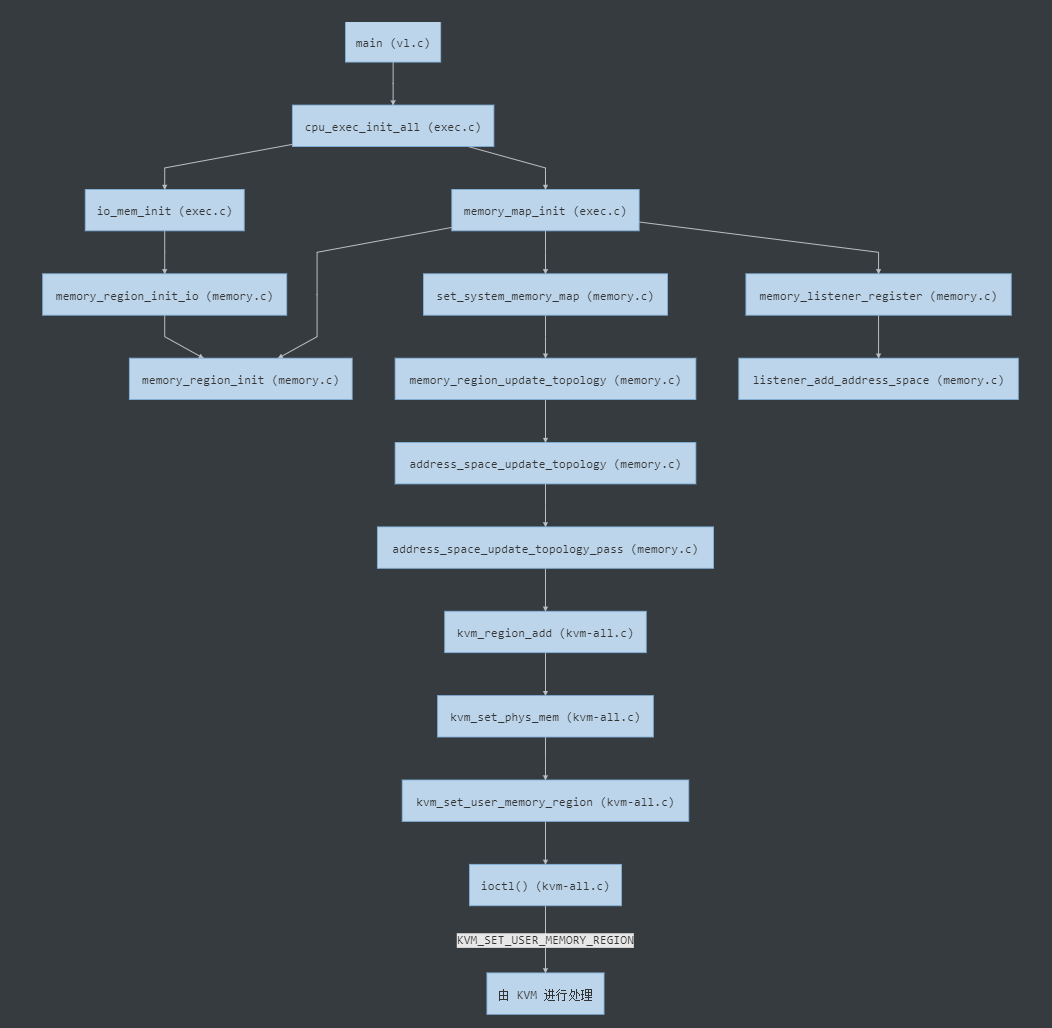
int main()
└─ void cpu_exec_init_all()
├─ static void memory_map_init()
| ├─ void memory_region_init() // 初始化 system_memory/io 这两个全局 MemoryRegion
| ├─ void set_system_memory_map() // address_space_memory->root = system_memory
| | └─ static void memory_region_update_topology() // 为 MemoryRegion 生成 FlatView
| | └─ static void address_space_update_topology() // as->current_map = new_view
| | └─ static void address_space_update_topology_pass()
| | └─ static void kvm_region_add() // region_add 对应的回调实现
| | └─ static void kvm_set_phys_mem() // 根据传入的 section 填充 KVMSlot
| | └─ static int kvm_set_user_memory_region()
| | └─ int ioctl(KVM_SET_USER_MEMORY_REGION)
| |
| └─ void memory_listener_register() // 注册对应的 MemoryListener
| └─ static void listener_add_address_space()
|
└─ static void io_mem_init()
└─ void memory_region_init_io() // ram/rom/unassigned/notdirty/subpage-ram/watch
└─ void memory_region_init()
第一部分在全局注册了kvm_memory_listener,但由于 AddressSpace 尚未初始化,实际上并未向 KVM 中注册任何实际的内存信息。QEMU 在main()函数中会继续调用cpu_exec_init_all()对 AddressSpace 进行初始化,该函数实际上是对两个 init 函数的封装调用:
void cpu_exec_init_all(void)
{
#if !defined(CONFIG_USER_ONLY)
memory_map_init(); // 初始化两个全局 AddressSpace,以及对应的 MemoryRegion、FlatView
io_mem_init(); // 初始化六个I/O MemoryRegion
#endif
}
先来看memory_map_init(),主要用来初始化两个全局的系统地址空间system_memory、system_io:
static void memory_map_init(void)
{
system_memory = g_malloc(sizeof(*system_memory));
memory_region_init(system_memory, "system", INT64_MAX); // 1. 初始化 system_memory
set_system_memory_map(system_memory); // 2. 设置 address_space_memory 关联 system_memory 及其对应的 FlatView
system_io = g_malloc(sizeof(*system_io));
memory_region_init(system_io, "io", 65536); // 1. 初始化 system_io
set_system_io_map(system_io); // 2. 设置 address_space_io 关联 system_io 及其对应的 FlatView
memory_listener_register(&core_memory_listener, system_memory); // 3. 注册 core_memory_listener
memory_listener_register(&io_memory_listener, system_io); // 3. 注册 io_memory_listener
}
这样一来就完成了以下对应关系:
AddressSpace address_space_memory address_space_io
↓ ↓
MemoryRegion system_memory system_io
↑ ↑
MemoryRegionListener core_memory_listener io_memory_listener
| AddressSpace | 对应的 MemoryRegion | 对应的 MemoryRegionListener |
|---|---|---|
| address_space_memory | system_memory | core_memory_listener |
| address_space_io | system_io | io_memory_listener |
memory_region_init主要是初始化system_memory的各个字段,这里比较重要的是set_system_memory_map(),先设置 AddressSpace 对应的 MemoryRegion,之后根据system_memory更新address_space_memory对应的 FlatView:
void set_system_memory_map(MemoryRegion *mr)
{
address_space_memory.root = mr; // 将 address_space_memory 的 root 域指向 system_memory
memory_region_update_topology(NULL); // 根据 system_memory 更新 address_space_memory 对应的 FlatView
}
而memory_region_update_topology()则会继续调用address_space_update_topology(),生成 AddressSpace 对应的 FlatView 视图:
static void memory_region_update_topology(MemoryRegion *mr)
{
// 此时仅在全局注册了 kvm_memory_listener,而 kvm_begin() 为空,无实际操作
MEMORY_LISTENER_CALL_GLOBAL(begin, Forward);
if (address_space_memory.root) { // 更新 address_space_memory 的 FlatView
address_space_update_topology(&address_space_memory);
}
if (address_space_io.root) { // 更新 address_space_io 的 FlatView
address_space_update_topology(&address_space_io);
}
// 此时仅在全局注册了 kvm_memory_listener,而 kvm_commit() 为空,无实际操作
MEMORY_LISTENER_CALL_GLOBAL(commit, Forward);
memory_region_update_pending = false;
}
address_space_update_topology()会先调用generate_memory_topology()生成system_memory更新后的视图new_view,再将address_space_memory的current_map指向这个new_view,最后销毁old_view:
static void address_space_update_topology(AddressSpace *as)
{
FlatView old_view = as->current_map;
FlatView new_view = generate_memory_topology(as->root); // 根据 system_memory 生成 new_view
// 入参 adding 为 false 时将调用 kvm_region_del()
address_space_update_topology_pass(as, old_view, new_view, false);
// 入参 adding 为 true 时将调用 kvm_region_add()
address_space_update_topology_pass(as, old_view, new_view, true);
as->current_map = new_view; // 指向 new_view
flatview_destroy(&old_view); // 销毁 old_view
address_space_update_ioeventfds(as);
}
在address_space_update_topology_pass()的最后,会调用MEMORY_LISTENER_UPDATE_REGION这个宏,触发region_add对应的回调函数kvm_region_add():
static void address_space_update_topology_pass(AddressSpace *as,
FlatView old_view,
FlatView new_view,
bool adding)
{
unsigned iold, inew;
FlatRange *frold, *frnew;
/* Generate a symmetric difference of the old and new memory maps.
* Kill ranges in the old map, and instantiate ranges in the new map.
*/
/* ... */
} else {
/* In new */
if (adding) {
MEMORY_LISTENER_UPDATE_REGION(frnew, as, Forward, region_add);
}
++inew;
}
}
}
这个宏在memory.c中定义,会将 FlatView 中的 FlatRange 转换为 MemoryRegionSection,作为入参传递给kvm_region_add():
#define MEMORY_LISTENER_UPDATE_REGION(fr, as, dir, callback) \
MEMORY_LISTENER_CALL(callback, dir, (&(MemoryRegionSection) { \
.mr = (fr)->mr, \
.address_space = (as)->root, \
.offset_within_region = (fr)->offset_in_region, \
.size = int128_get64((fr)->addr.size), \
.offset_within_address_space = int128_get64((fr)->addr.start), \
.readonly = (fr)->readonly, \
}))
而kvm_region_add()实际上是对kvm_set_phys_mem()的封装调用。该函数比较复杂,会根据传入的section填充 KVMSlot,再传递给kvm_set_user_memory_region():
static int kvm_set_user_memory_region(KVMState *s, KVMSlot *slot)
{
struct kvm_userspace_memory_region mem;
mem.slot = slot->slot; // 根据 KVMSlot 填充 kvm_userspace_memory_region
mem.guest_phys_addr = slot->start_addr;
mem.memory_size = slot->memory_size;
mem.userspace_addr = (unsigned long)slot->ram;
mem.flags = slot->flags;
if (s->migration_log) {
mem.flags |= KVM_MEM_LOG_DIRTY_PAGES;
}
return kvm_vm_ioctl(s, KVM_SET_USER_MEMORY_REGION, &mem);
}
可以看到这里又将 KVMSlot 转换为 kvm_userspace_memory_region,作为ioctl()的参数,交给内核中的 KVM 进行内存的注册。至此 QEMU 侧负责管理内存的数据结构均已完成初始化,可以参考下面的图片了解各数据结构之间的对应关系:
最后简单看下io_mem_init(),调用memory_region_init_io()对六个 I/O MemoryRegion 进行初始化:
static void io_mem_init(void)
{
memory_region_init_io(&io_mem_ram, &error_mem_ops, NULL, "ram", UINT64_MAX);
memory_region_init_io(&io_mem_rom, &rom_mem_ops, NULL, "rom", UINT64_MAX);
memory_region_init_io(&io_mem_unassigned, &unassigned_mem_ops, NULL, "unassigned", UINT64_MAX);
memory_region_init_io(&io_mem_notdirty, ¬dirty_mem_ops, NULL, "notdirty", UINT64_MAX);
memory_region_init_io(&io_mem_subpage_ram, &subpage_ram_ops, NULL, "subpage-ram", UINT64_MAX);
memory_region_init_io(&io_mem_watch, &watch_mem_ops, NULL, "watch", UINT64_MAX);
}
- io_mem_ram,名为 “ram”
- io_mem_rom,名为 “rom”
- io_mem_unassigned,名为 “unassigned”
- io_mem_notdirty,名为 “notdirty”
- io_mem_subpage_ram,名为 “subpage-ram”
- io_mem_warch,名为 “watch”
而memory_region_init_io()则会先调用memory_region_init()对上述六个 MemoryRegion 进行初始化,之后设置一些字段的值:
void memory_region_init_io(MemoryRegion *mr,
const MemoryRegionOps *ops,
void *opaque,
const char *name,
uint64_t size)
{
memory_region_init(mr, name, size);
mr->ops = ops;
mr->opaque = opaque;
mr->terminates = true; // 表示为实体类型的 MemoryRegion
mr->destructor = memory_region_destructor_iomem;
mr->ram_addr = ~(ram_addr_t)0;
}
3.3 实际内存的分配
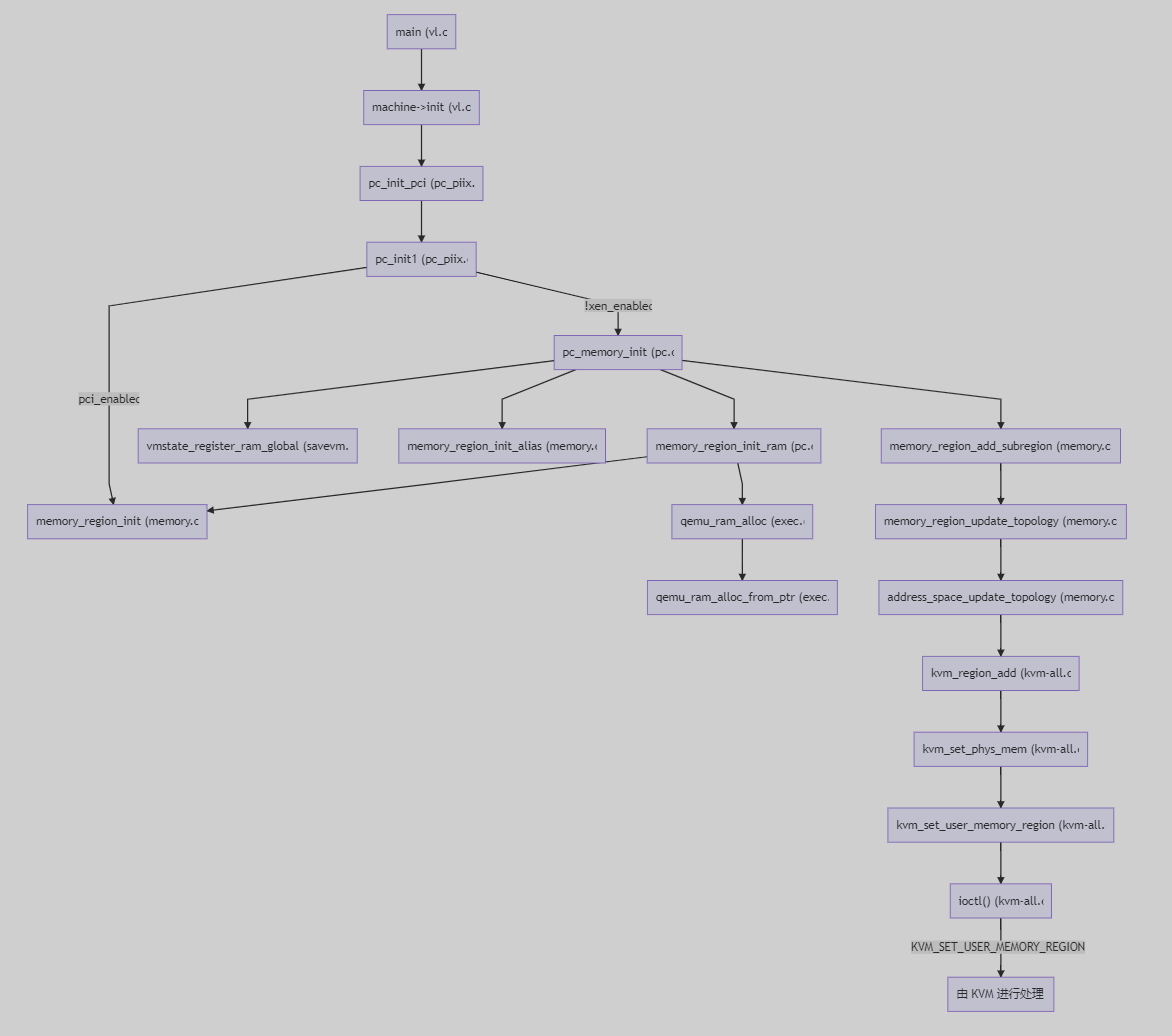
int main()
└─ void machine->init(ram_size, ...)
└─ static void pc_init_pci(ram_size, ...) // 初始化虚拟机
└─ static void pc_init1(system_memory, system_io, ram_size, ...)
├─ void memory_region_init(pci_memory, "pci", ...) // pci_memory, rom_memory
└─ void pc_memory_init() // 初始化内存,分配实际的物理内存地址
├─ void memory_region_init_ram() // 创建 pc.ram, pc.rom 并分配内存
| ├─ void memory_region_init()
| └─ ram_addr_t qemu_ram_alloc()
| └─ ram_addr_t qemu_ram_alloc_from_ptr()
|
├─ void vmstate_register_ram_global() // 将 MR 的 name 写入 RAMBlock 的 idstr
| └─ void vmstate_register_ram()
| └─ void qemu_ram_set_idstr()
|
├─ void memory_region_init_alias() // 初始化 ram_below_4g, ram_above_4g
└─ void memory_region_add_subregion() // 在 system_memory 中添加 subregions
└─ static void memory_region_add_subregion_common()
└─ static void memory_region_update_topology() // 为 MemoryRegion 生成 FlatView
└─ static void address_space_update_topology() // as->current_map = new_view
└─ static void address_space_update_topology_pass()
└─ static void kvm_region_add() // region_add 对应的回调实现
└─ static void kvm_set_phys_mem() // 根据传入的 section 填充 KVMSlot
└─ static int kvm_set_user_memory_region()
└─ int ioctl(KVM_SET_USER_MEMORY_REGION)
之前的回调函数注册、AddressSpace 的初始化,实际上均没有对应的物理内存。顺着main()函数往下走,会来到pc_init_pci()这个函数。
函数pc_init_pci()负责在 QEMU 中初始化虚拟机,内存的虚拟化也是在这里完成的。调用machine->init()时传入了ram_size参数,表示申请内存的大小,一步步传递给了pc_init1()。
在pc_init1()中,先将ram_size分为above_4g_mem_size、below_4g_mem_size,之后调用pc_memory_init()对内存进行初始化:
void *pc_memory_init(MemoryRegion *system_memory,
const char *kernel_filename,
const char *kernel_cmdline,
const char *initrd_filename,
ram_addr_t below_4g_mem_size,
ram_addr_t above_4g_mem_size,
MemoryRegion *rom_memory,
MemoryRegion **ram_memory)
{
MemoryRegion *ram, *option_rom_mr; // 两个实体 MR: pc.ram, pc.rom
MemoryRegion *ram_below_4g, *ram_above_4g; // 两个别名 MR: ram_below_4g, ram_above_4g
/* Allocate RAM. We allocate it as a single memory region and use
* aliases to address portions of it, mostly for backwards compatibility
* with older qemus that used qemu_ram_alloc().
*/
ram = g_malloc(sizeof(*ram)); // 创建 ram
// 分配具体的内存(实际上会创建一个 RAMBlock 并将其 offset 值写入 ram.ram_addr,对应 GPA)
memory_region_init_ram(ram, "pc.ram", below_4g_mem_size + above_4g_mem_size);
// 将 MR 的 name 写入 RAMBlock 的 idstr
vmstate_register_ram_global(ram);
*ram_memory = ram;
// 创建 ram_below_4g 表示 4G 以下的内存
ram_below_4g = g_malloc(sizeof(*ram_below_4g));
memory_region_init_alias(ram_below_4g, "ram-below-4g", ram, 0, below_4g_mem_size);
// 将 ram_below_4g 挂在 system_memory 下
memory_region_add_subregion(system_memory, 0, ram_below_4g);
if (above_4g_mem_size > 0) {
ram_above_4g = g_malloc(sizeof(*ram_above_4g));
memory_region_init_alias(ram_above_4g, "ram-above-4g", ram, below_4g_mem_size, above_4g_mem_size);
memory_region_add_subregion(system_memory, 0x100000000ULL, ram_above_4g);
}
/* ... */
}
这里的重点在于memory_region_init_ram(),它通过qemu_ram_alloc()获取ram这个 MemoryRegion 对应的 RAMBlock 的offset,并存入ram.ram_addr,这样就可以在ram_list中根据该字段查找 MR 对应的 RAMBlock:
void memory_region_init_ram(MemoryRegion *mr, const char *name, uint64_t size)
{
memory_region_init(mr, name, size); // 填充字段,初始化默认值
mr->ram = true; // 表示为 RAM
mr->terminates = true; // 表示为实体 MemoryRegion
mr->destructor = memory_region_destructor_ram;
mr->ram_addr = qemu_ram_alloc(size, mr); // 这里保存 RAMBlock 的 offset,即 GPA
}
而qemu_ram_alloc()最终会调用qemu_ram_alloc_from_ptr(),创建一个对应大小 RAMBlock 并分配内存,返回对应的 GPA 地址存入mr->ram_addr中:
ram_addr_t qemu_ram_alloc_from_ptr(ram_addr_t size, void *host,
MemoryRegion *mr)
{
RAMBlock *new_block; // 创建一个 RAMBlock
size = TARGET_PAGE_ALIGN(size); // 页对齐
new_block = g_malloc0(sizeof(*new_block)); // 初始化 new_block
new_block->mr = mr; // 将 new_block-> 指向入参的 MemoryRegion
new_block->offset = find_ram_offset(size); // 从 ram_list 中的 RAMBlock 之间找到一段可以满足 size 需求的 gap,并返回起始地址的 offset,对应 GPA
if (host) { // 新建的 RAMBlock host 字段为空,跳过
new_block->host = host;
new_block->flags |= RAM_PREALLOC_MASK;
} else {
if (mem_path) { // 未指定 mem_path
#if defined (__linux__) && !defined(TARGET_S390X)
new_block->host = file_ram_alloc(new_block, size, mem_path);
if (!new_block->host) {
new_block->host = qemu_vmalloc(size);
qemu_madvise(new_block->host, size, QEMU_MADV_MERGEABLE);
}
#else
fprintf(stderr, "-mem-path option unsupported\n");
exit(1);
#endif
} else {
if (xen_enabled()) {
xen_ram_alloc(new_block->offset, size, mr);
} else if (kvm_enabled()) { // 从这里继续
/* some s390/kvm configurations have special constraints */
new_block->host = kvm_vmalloc(size); // 实际上还是调用 qemu_vmalloc(size)
} else {
new_block->host = qemu_vmalloc(size); // 从 QEMU 的线性空间中分配 size 大小的内存,返回 HVA
}
qemu_madvise(new_block->host, size, QEMU_MADV_MERGEABLE);
}
}
new_block->length = size; // 将 length 设置为 size
QLIST_INSERT_HEAD(&ram_list.blocks, new_block, next); // 将该 RAMBlock 插入 ram_list 头部
ram_list.phys_dirty = g_realloc(ram_list.phys_dirty, // 重新分配 ram_list.phys_dirty 的内存空间
last_ram_offset() >> TARGET_PAGE_BITS);
memset(ram_list.phys_dirty + (new_block->offset >> TARGET_PAGE_BITS),
0, size >> TARGET_PAGE_BITS);
cpu_physical_memory_set_dirty_range(new_block->offset, size, 0xff); // 对该 RAMBlock 对应的内存标记为 dirty
qemu_ram_setup_dump(new_block->host, size);
if (kvm_enabled())
kvm_setup_guest_memory(new_block->host, size);
return new_block->offset;
}
这样一来ram对应的 RAMBlock 中就分配好了 GPA 和 HVA,就可以将内存信息同步至 KVM 侧了。
最后回到pc_memory_init()中,在分配完实际内存后,会先调用memory_region_init_alias()初始化ram_below_4g、ram_above_4g这两个 alias,之后调用memory_region_add_subregion()将这两个 alias 指向ram这个实体 MemoryRegion。该函数最终会触发kvm_region_add()回调,将实际的内存信息传入 KVM 注册。该过程如下图所示,与之前分析的流程相同,此处不再赘述。
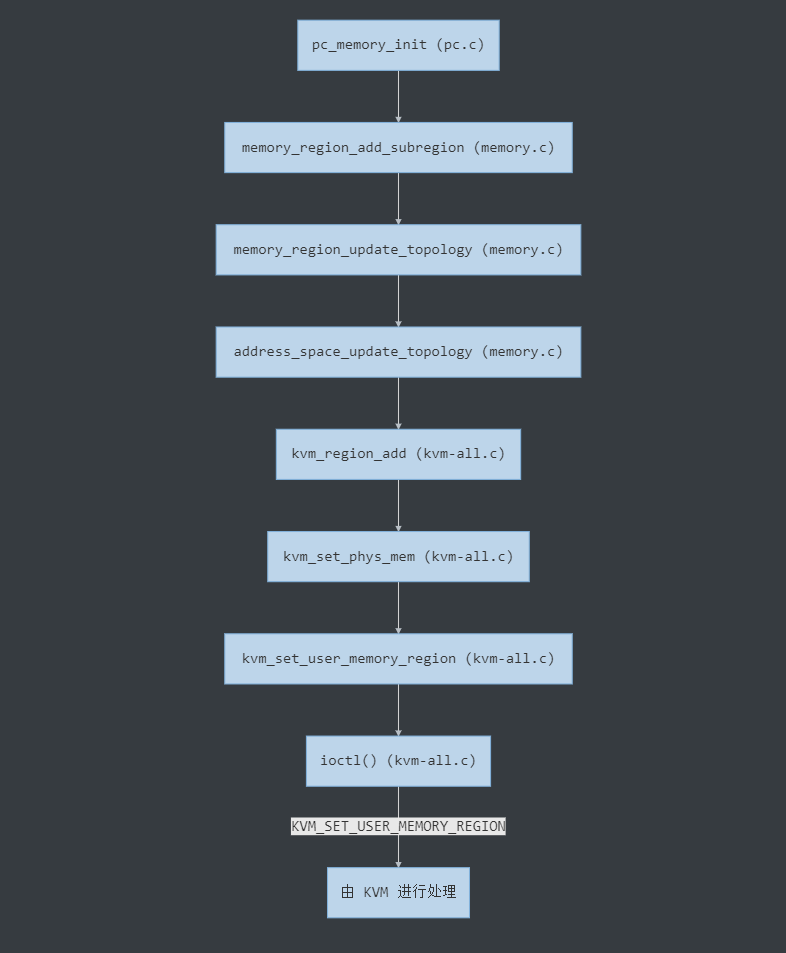
4. 总结一下
4.1 QEMU 侧
- 创建一系列 MemoryRegion,分别表示 Guest 中的 RAM、ROM 等区域。MemoryRegion 之间通过 alias 或 subregions 的方式维护相互之间的关系,从而进一步细化区域的定义
- 对于一个实体 MemoryRegion(非 alias),在初始化内存的过程中 QEMU 会创建它所对应的 RAMBlock。该 RAMBlock 通过调用
qemu_ram_alloc_from_ptr()从 QEMU 的进程地址空间中以 mmap 的方式分配内存,并负责维护该 MemoryRegion 对应内存的起始 GPA/HVA/size 等相关信息 - AddressSpace 表示 Guest 的物理地址空间。如果 AddressSpace 中的 MemoryRegion 发生变化,则注册的 listener 会被触发,将所属的 MemoryRegion 树展开生成一维的 FlatView,比较 FlatRange 是否发生了变化。如果是则调用相应的方法对 MemoryRegionSection 进行检查,更新 QEMU 中的 KVMSlot,同时填充
kvm_userspace_memory_region结构体,作为ioctl()的参数更新 KVM 中的kvm_memory_slot
4.2 KVM 侧
- 当 QEMU 通过
ioctl()创建 vcpu 时,调用kvm_mmu_create()初始化 MMU 相关信息 - 当 KVM 要进入 Guest 前,
vcpu_enter_guest()=>kvm_mmu_reload()会将根级页表地址加载到 VMCS,让 Guest 使用该页表 - 当发生 EPT Violation 时,VM-EXIT 到 KVM 中。如果是缺页,则根据 GPA 算出 gfn,再根据 gfn 找到对应的 KVMSlot,从中得到对应的 HVA。然后根据 HVA 算出对应的 pfn,确保该 Page 位于内存中。填好缺失的页之后,需要更新 EPT,完善其中缺少的页表项,逐层补全页表
参考文章
干货
- 【系列分享】QEMU 内存虚拟化源码分析 | 安全客
- QEMU学习笔记——内存 | BinSite
- QEMU-KVM 内存虚拟化 1 | cnblogs
- QEMU-KVM 内存虚拟化 2 | cnblogs
- QEMU 中的内存管理 - 前进的code | cnblogs
- KVM 虚拟化原理探究(4)— 内存虚拟化 | cnblogs
- QEMU 内存管理之生成 FlatView 内存拓扑模型过程分析(基于QEMU 2.0.0)- eric_liufeng
- QEMU-KVM 内存虚拟化 | 王子阳
- QEMU 对虚拟机的地址空间管理 - Jessica 要努力了 | cnblogs
- QEMU-KVM 部分流程/源代码分析(多图)| kk Blog
- QEMU 深入浅出: Guest物理内存管理 | IBM 中国 Linux 与虚拟化实验室
阿里云 Bozh
- KVM 虚拟化原理探究(1) —— Overview | 博客园
- KVM 虚拟化原理探究(2) —— QEMU 启动过程 | 博客园
- KVM 虚拟化原理探究(3) —— CPU 虚拟化 | 博客园
- KVM 虚拟化原理探究(4) —— 内存虚拟化 | 博客园
- KVM 虚拟化原理探究(5) —— 网络 I/O 虚拟化 | 博客园
- KVM 虚拟化原理探究(6) —— 块设备 I/O 虚拟化 | 博客园
太初有道
- intel EPT 机制详解 - 太初有道 | 博客园
- KVM 中 EPT 逆向映射机制分析 - 太初有道 | 博客园
- QEMU 进程页表和 EPT 的同步问题 - 太初有道 | 博客园
- QEMU-KVM 内存虚拟化 1 - 太初有道 | 博客园
- QEMU-KVM 内存虚拟化 2 - 太初有道 | 博客园
- Linux 下的 KSM 内存共享机制分析 - 太初有道 | 博客园
- KVM 中断虚拟化浅析 - 太初有道 | 博客园
- KVM vCPU 线程调度问题的讨论 - 太初有道| 博客园
OenHan
KVM 虚拟化
- KVM 源代码分析 1: 基本工作原理 | OenHan
- KVM 源代码分析 2: 虚拟机的创建与运行 | OenHan
- KVM 源代码分析 3: CPU 虚拟化 | OenHan
- KVM 源代码分析 4: 内存虚拟化 | OenHan
- KVM 源代码分析 5: I/O 虚拟化之 PIO | OenHan
- QEMU 下的内存结构 MemoryRegion 和 AddressSpace | OenHan
- KVM CLOCK 时钟虚拟化源代码分析 | OenHan
- KVM MMU Page 释放机制 | OenHan
其他
- TOPIC | OenHan
- CPU 亲和性的使用与机制 | OenHan
- CGROUP 源码分析 1: 基本概念与框架 | OenHan
- 从一次内存泄露看程序在内核中的执行过程 | OenHan
- Linux 缓存写回机制 | OenHan
leoufung
- QEMU内存管理之生成 FlatView 内存拓扑模型过程分析(基于QEMU2.0.0)| CSDN
- QEMU 内存管理之 FlatView 模型(QEMU2.0.0)| CSDN
- kvm_mmu_get_page 函数解析 | CSDN
- tdp_page_fault 函数解析之 level, gfn 变量的含义 | CSDN
- QEMU 中通过 GPA 得到对应 HVA 的方法 | CSDN
- kvm_mmu_page 结构和用法解析(基于Kernel3.10.0)| CSDN
- 通过 KVM_SET_USER_MEMORY_REGION 操作虚拟机内存(Kernel 3.10.0 & qemu 2.0.0)| CSDN
- QEMU 的 AddrRange 地址空间对象模型算法总结(QEMU2.0.0) | CSDN
- QEMU 内存管理之 FlatView 模型(QEMU2.0.0)| CSDN
- MemoryRegion 模型原理,以及同 FlatView 模型的关系(QEMU2.0.0) | CSDN
- 如何查看系统中都注册了哪些 MemoryRegion (QEMU2.0.0) | CSDN
- QEMU 中关于 CPU 初始化的重要函数调用栈 | CSDN
- 如何调试 QEMU | CSDN
- 单独编译 KVM 模块的方法(进行调试) | CSDN
- kvm 代码中 vcpu_vmx、vcpu、vmcs、cpu 的关系 | CSDN
论文 and PPT
- Fast Write Protection - 肖光荣 | PDF
- Nested paging hardware and software - KVM Forum 2018 | PDF
- Accelerating Two-Dimensional Page Walks for Virtualized Systems | PDF
intel 白皮书
- Intel 64 and IA-32 Architectures Software Developer’s Manual | PDF
- 5-Level Paging and 5-Level EPT | PDF
- Page Modification Logging for Virtual Machine Monitor White Paper | PDF
- Intel 64 架构 5 级分页和 5 级 EPT 白皮书 | 简书
EPT & MMU
- EPT 缺页异常源码分析 | Benxi Liu
- VT-x/EPT 解读 | Benxi Liu
- 关于中断虚拟化 | Benxi Liu
- 梳理一下 EPT 表项的建立 | GeekBen
- KVM 地址翻译流程及 EPT 页表的建立过程 | CSDN
- tdp_page_fault 函数解析之 level,gfn 变量的含义 | CSDN
- EPT Page Fault Procedure
- KVM 中的 EPT Exception | Blogger
- KVM 内存访问采样(一)—— 扩展页表 EPT 的结构 | 周语馨
- KVM 的 EPT 机制 | 博客园
- EPT page fault procedure | KVM Mailing List
- 科普 VT、EPT | 简书
- Memory | KVM Documents
- mmu.txt | KVM
- KVM MMU EPT 内存管理 | CSDN
- qemu-kvm 内存虚拟化 - ept | CSDN
- KVM MMU EPT 内存管理 | 学佳园
Patchwork
常用网站
- KVM development | Patchwork
- QEMU patches | Patchwork
- Bootlin - Elixir Cross Reference | 在线阅读 Kernel、QEMU 源码
- rpmfind | 用来找 rpm 包
- kernel-3.10.0-957.el7 RPM for x86_64 | rpmfind
- KVM: x86: implement ring-based dirty memory tracking | kvm.git
肖光荣 Fast Write Protect-v1
- [0/7] KVM: MMU: fast write protect | Patchwork
- [1/7] KVM: MMU: correct the behavior of mmu_spte_update_no_track | Patchwork
- [2/7] KVM: MMU: introduce possible_writable_spte_bitmap | Patchwork
- [3/7] KVM: MMU: introduce kvm_mmu_write_protect_all_pages | Patchwork
- [4/7] KVM: MMU: enable KVM_WRITE_PROTECT_ALL_MEM | Patchwork
- [5/7] KVM: MMU: allow dirty log without write protect | Patchwork
- [6/7] KVM: MMU: clarify fast_pf_fix_direct_spte | Patchwork
- [7/7] KVM: MMU: stop using mmu_spte_get_lockless under mmu-lock | Patchwork
肖光荣 Fast Write Protect-v2
- [v2,0/7] KVM: MMU: fast write protect | Patchwork | Patchwork
- [v2,1/7] KVM: MMU: correct the behavior of mmu_spte_update_no_track | Patchwork
- [v2,2/7] KVM: MMU: introduce possible_writable_spte_bitmap | Patchwork
- [v2,3/7] KVM: MMU: introduce kvm_mmu_write_protect_all_pages | Patchwork
- [v2,4/7] KVM: MMU: enable KVM_WRITE_PROTECT_ALL_MEM | Patchwork
- [v2,5/7] KVM: MMU: allow dirty log without write protect | Patchwork
- [v2,6/7] KVM: MMU: clarify fast_pf_fix_direct_spte | Patchwork
- [v2,7/7] KVM: MMU: stop using mmu_spte_get_lockless under mmu-lock | Patchwork
Mailing List
- [PATCH v2 0/7] KVM: MMU: fast write protect | LKML
- Re: [Qemu-devel] [PATCH 0/7] KVM: MMU: fast write protect | gnu.org
patch 教程
- 如何给 Linux 内核打补丁 | 一根稻草
- diff 和 patch 的入门(及 Windows 下的用法)| orzfly.com
- 补丁(patch)的制作与应用 | Linux-Wiki.cn
- Linux 内核补丁与 patch/diff 使用详解 | CSDN
升级内核
内存虚拟化基础
地址空间
- 操作系统 内存地址(逻辑地址、线性地址、物理地址)概念 | CSDN
- 物理地址、虚拟地址(线性地址)、逻辑地址以及MMU的知识 | CSDN
- PCIe 的内存地址空间、I/O 地址空间和配置地址空间 | CSDN
- Linux 线性地址,逻辑地址和虚拟地址的关系?| 知乎
- Linux 中的物理地址、虚拟地址、总线地址的区别 | CSDN
- 物理地址和总线地址的区别 | CSDN
mmap
QEMU 部分
- 【干货!】【系列分享】QEMU内存虚拟化源码分析 | 安全客
- QEMU-KVM 内存虚拟化 | 王子阳
- QEMU 学习笔记 —— 内存 | BinSite
- QEMU 中的内存管理 - 前进的code| cnblogs
- QEMU 对虚拟机的地址空间管理 - Jessica 要努力了 | cnblogs
- QEMU 内存管理之生成 FlatView 内存拓扑模型过程分析(基于 QEMU 2.0.0)| leoufung
- Qemu 内存管理代码分析 1:qemu (tag: v3.0.0-rc1) 命令行配置 guest ram 及 machine_class_init 的 QOM 调用 | CSDN
- Qemu 内存管理主要结构体分析 2:MemoryRegion/AddressSpace/FlatView | CSDN
- Qemu 内存管理代码分析 3:guest ram 的初始化及分配 | CSDN
- qemu-kvm 部分流程/源代码分析(多图)| kk Blog
- QEMU深入浅出: guest物理内存管理 | IBM 中国 Linux 与虚拟化实验室
- QEMU 对虚机的地址空间管理 | 阿里云栖社区
- QEMU 内存管理 | 腾讯云+社区
- QEMU 中的内存管理介绍 | CSDN
KVM 部分
- KVM 初始化过程 | liujunming.top
- KVM 内核模块重要的数据结构 | liujunming.top
- KVM 内存虚拟化及其实现 | IBM Developer
- CPU 体系架构 - MMU | NieNet
- TLB 和 MMU 的区别 | 博客园
- MMU 和 Cache 详解(TLB 机制)| CSDN
- x86 虚拟化概述 | BinSite
其他
- KVM,QEMU 核心分析 | 博客园
- 内存虚拟化到底是咋整的?- 腾讯云 TStack | 腾讯云+社区
- 从kvm场景下guest访问的内存被swap出去之后说起 | kernelnote
- linux 下 cpu load 和 cpu 使用率的关系 | kernelnote
- 关于linux下进程栈的研究 | kernelnote
- 虚拟化环境中的hypercall介绍 | kernelnote
- linux ksm 内存 merge机制研究 | kernelnote
- KVM 虚拟化之 VM Exit/Entry | Min’s Blog
- QEMU Internals: How guest physical RAM works | Stefan Hajnoczi
- kvm: virtual x86 mmu setup | Davidlohr Bueso
- GDB 调试 QEMU 源码记录 - 太初有道 | cnblogs
- SIG@QEMU-KVM - kernel-dev-environment | Github
- 向大家汇报,我们连续第二年登上KVM全球开源贡献榜 | 腾讯开源

